
因子変数
因子(カテゴリ)変数の扱いがよりエレガントなものとなりました。変数名の前にi. という演算子を付加することによって、それぞれのレベル(カテゴリ)を指標変数で表現するよう指示することが可能になりました。2変数間を # で結合することにより、交互作用項を表現することができます。この場合、カテゴリのそれぞれの組合せが指標変数によって表現されます。## という演算子を用いた場合には交互作用以外に主効果も含まれることになります。因子変数と連続変数間での交互作用も指定できます。ただしその場合には連続変数名の前に c. という演算子を付加する必要があります。最大8元の交互作用まで指定することができます。
次に示すものはコレステロールレベルに関する線形回帰モデルですが、説明変数として用いられているものは次の通りです。
- smoker(喫煙/非喫煙)と agegrp(年齢群)の全組合せ、すなわち主効果と交互作用
- bmi(ボディマス指標)
- smoker と bmi(連続変数)の交互作用
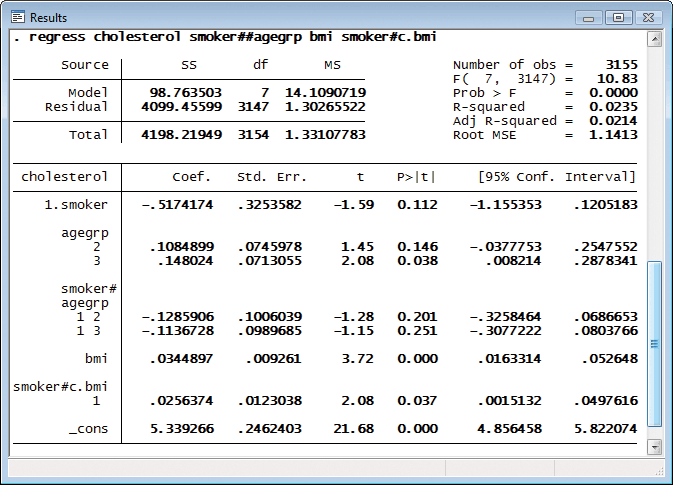
上記のコマンドは括弧を用いることによってさらに簡略化することができます。
. regress cholesterol smoker##(agegrp c.bmi)
ベースレベルを変更することもできます。i.agegrp と指定した場合にはデフォルトの1がベースレベルとして用いられますが、b3.agegrp という指定の場合には3がベースレベルとして用いられます。
使用される指標変数はデータセット中に生成されるわけではないのでスペースの節約が図れます。
因子変数はStataにおける変数リストの処理に深く根ざしているため、推定コマンドと推定事後機能コマンド間で不整合が生ずることはありません。
一般的な統計機能のエンハンス項目については こちら をクリックください。

