
データ読み込み
Excelファイルのインポート
unicodeをサポートしているので、日本語フォルダ・ファイルでも問題ありません
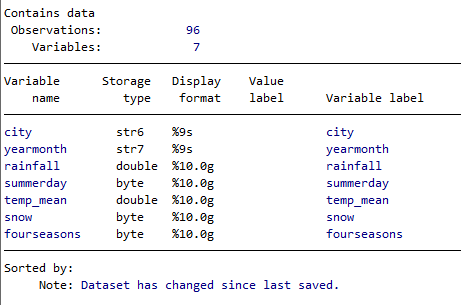
データセットの概要確認
観測数(行数)、変数の数(列数)、変数名、変数のタイプ、表示形式、変数ラベルをまとめて報告します
変数の内容確認
観測数、欠損値の数、固有値の数・パターン、範囲、平均、標準偏差をまとめて報告します。数値・文字列変数を一括で確認できます

データ読み込み(Python)
Excelファイル読み込み
import pandas as pd
df = pd.read_excel(r"C:\Users\nagai\Desktop\sampledata\sampledata.xlsx")
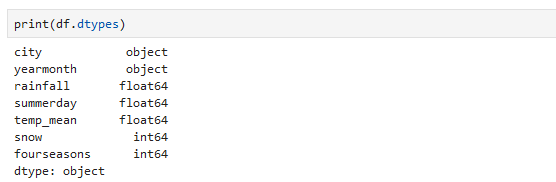
データセットの概要確認
print(df.dtypes())
変数の内容確認
print(df["city"].unque())

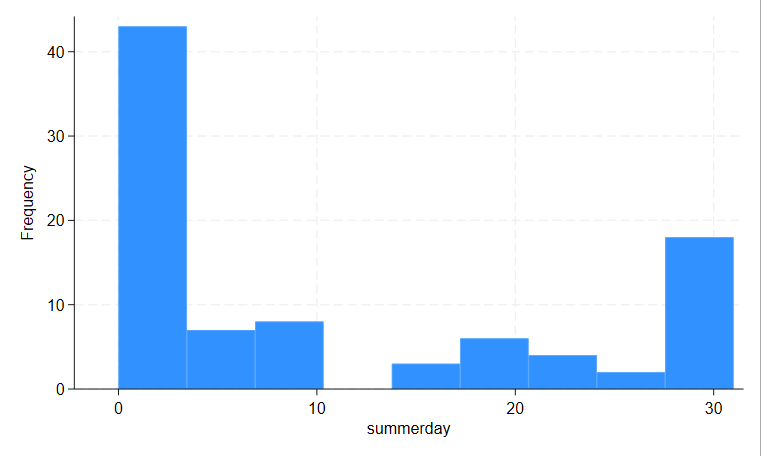
グラフ
ヒストグラム作成
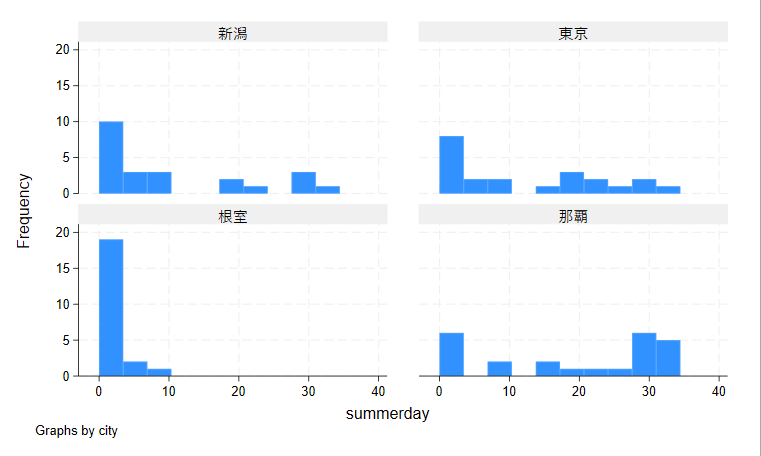
地域ごとにサブグラフを作成
by()でカテゴリを指定し、階級でグラフを分割できます
散布図
標本のサブグループを使用するには、if条件を追加し、カテゴリ・文字列変数の要素で指定します。
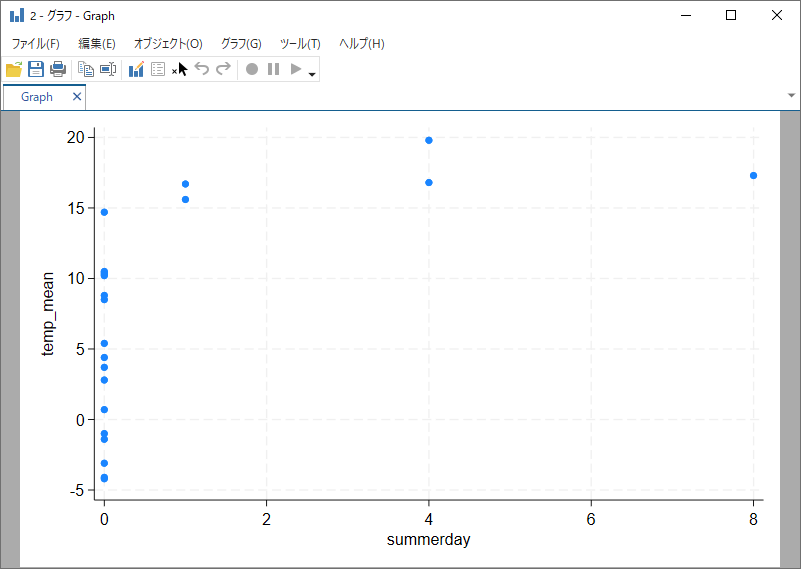
散布図をオーバーレイ
コマンドを並べるだけで、グラフをオーバーレイできます
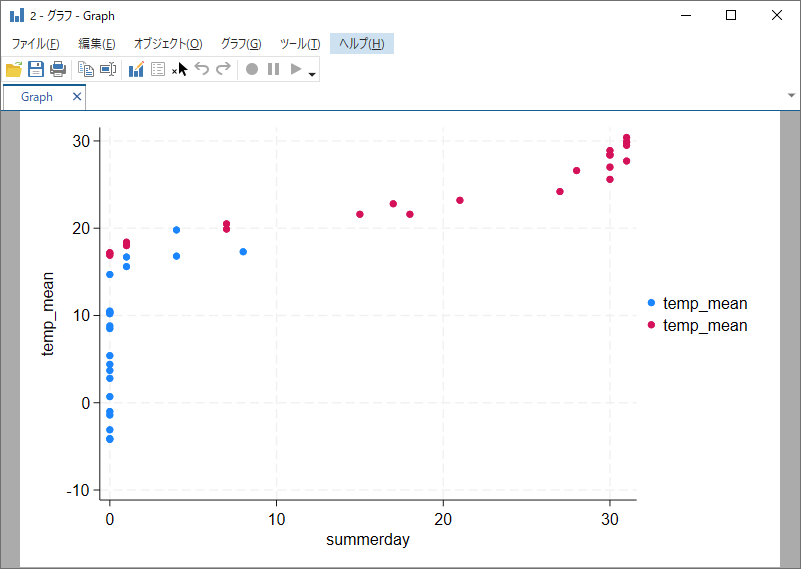
作成したグラフは、グラフエディタで簡単に編集できます
{kind=link}
グラフ(Python)
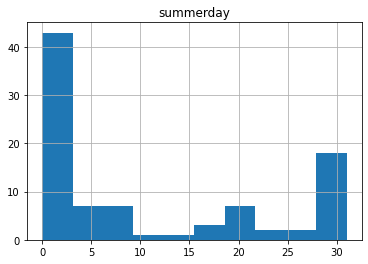
ヒストグラム作成
print(df.hist(column="summerday"))
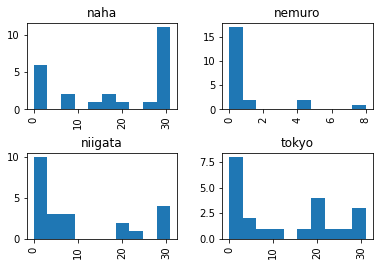
地域ごとにサブグラフを作成
matplotlibでは日本語文字が扱えないので、ラテン文字に置き換える必要があります
import seaborn as sns
def categorize(city):
if city == "根室":
return 'nemuro'
elif city == "東京":
return 'tokyo'
elif city == "新潟":
return "niigata"
else:
return 'naha'
df['ccode'] = df['city'].apply(categorize)
df["ccode"] = df["ccode"].astype("category")
print(df.hist(by="ccode", column="summerday"))
散布図
サブサンプルでグラフを作成するには、データフレームを新たに作成することになります
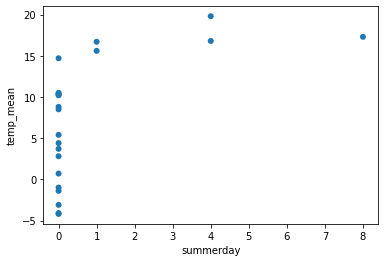
df2 = df[df["city"] == "根室"]
print(sns.scatterplot(data = df2, x = "summerday", y = "temp_mean", edgecolor = "none"))
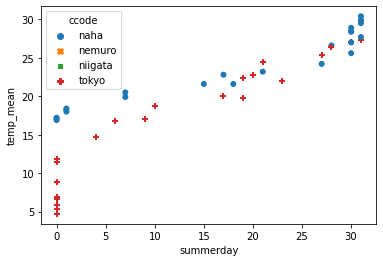
散布図をオーバーレイ
print(sns.scatterplot(data = df.where((df["city"] == "那覇") | (df["city"] == "東京") ), x = "summerday", y = "temp_mean", edgecolor = "none", hue = "ccode", style ="ccode"))
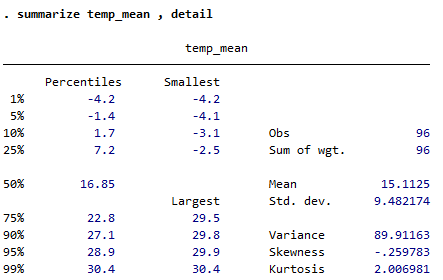
記述統計量と仮説検定
記述統計量の確認
標本数、加重の合計、平均、標準偏差、分散、尖度、歪度、分位点を報告できます
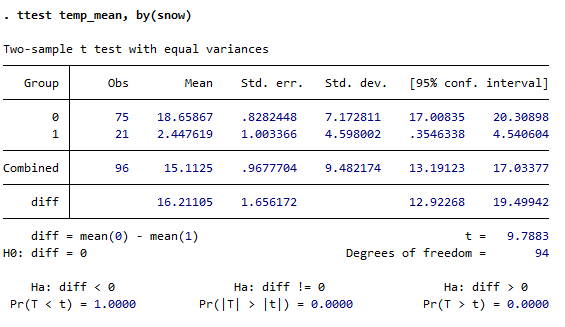
t検定
グループ変数をby()で指定し、群間の平均値の検定ができます。各群の標本数平均、標準誤差と帰無仮説、t統計量、片側・両側検定の各p値をまとめて報告します
記述統計量と仮説検定(Python)
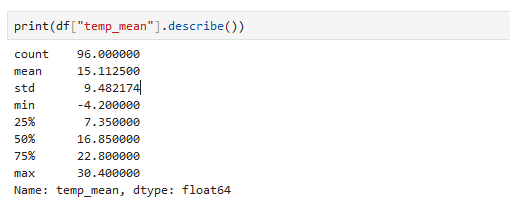
記述統計量
print(df["temp_mean"].describe())
t検定
カテゴリ変数で新たにデータフレームを分割する必要があります
from scipy import stats
group1 = df[df["snow"] == 0]["temp_mean"]
group2 = df[df["snow"] == 1]["temp_mean"]
print(stats.ttest_ind(group1, group2))

推定/診断/予測
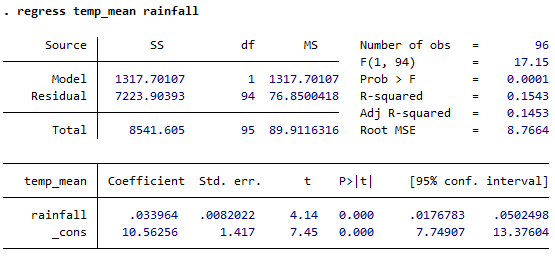
線形回帰
従属変数と独立変数を指定するだけで推定できます
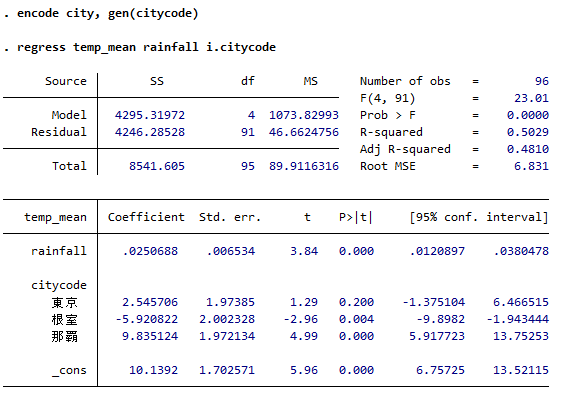
カテゴリ変数を説明変数に追加
文字列変数はencodeでカテゴリ変数に変換、値ラベルを追加できます
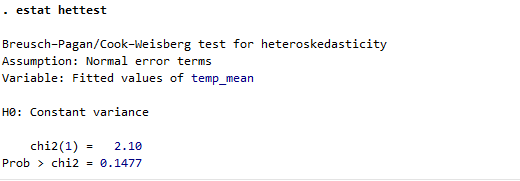
不均一分散の診断
検定方法、帰無仮説、検定統計量とp値を報告します
estat hettest
予測
直前の推定結果を利用し、標本内予測ができます
推定/診断/予測(Python)
線形回帰
from statsmodels.formula.api import ols
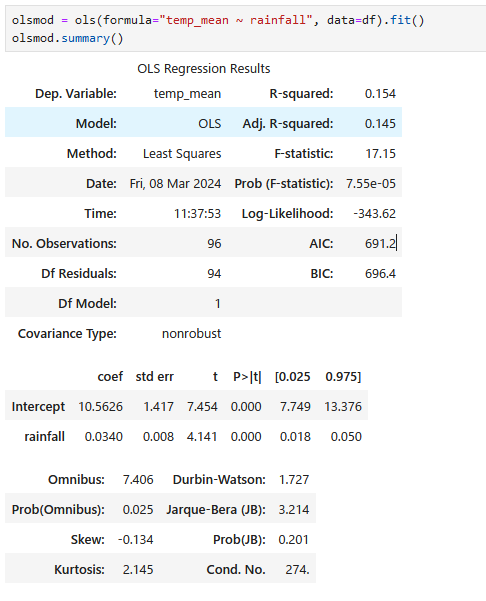
model1 = ols(formula="temp_mean ~ rainfall", data=df).fit()
print(model1.summary())
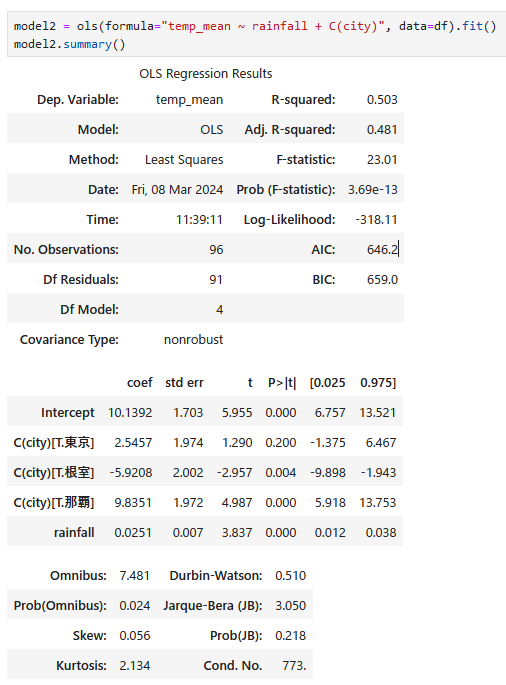
カテゴリ変数を説明変数に追加
model2 = ols(formula="temp_mean ~ rainfall + C(city)", data=df).fit()
print(mod2.summary())
不均一分散の診断
from statsmodels.stats.api import het_breuschpagan
print(het_breuschpagan(model2.resid, model2.model.exog))

予測
yhat = model2.predict
Stata is a registered trademark of StataCorp LLC, College Station, TX, USA, and the Stata logo is used with the permission of StataCorp.

ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2025 Lightstone Corp. All Rights Reserved