
データセットの一部を読込む
データセット全体ではなく、データセットの一部を使用したい場合があります。 一部の変数、一部の観測値、あるいはその両方を使用したい場合があります。 これは、コンピューターに搭載されているメモリ量よりも大きいデータセットがある場合によく発生します。 まず、データセットをコピーするため以下のように入力します。
. copy https://www.stata-press.com/data/r18/nhanes2l.dta nhanes2l.dta
次に、「describe using」と入力すると、データファイルを開かずにデータセットの内容に関する情報を表示できます。
. describe using nhanes2l.dta

データセットには 10,351 の観測値と 42 の変数が含まれています。 おそらく、私たちは diabetes、agegrp、bmi という変数だけに興味があります。 use コマンドにこれらの変数名を含めることができ、Stata はそれらの変数のみをメモリにロードします。
. use diabetes agegrp bmi using nhanes2l
「describe」と入力すると、メモリ内のデータの内容を表示できます。
. describe
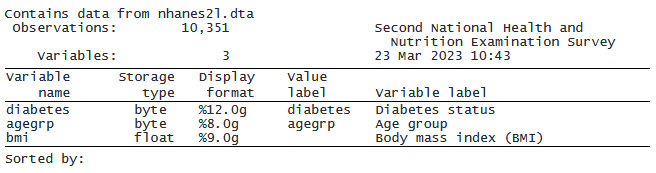
私たちがリクエストした変数 (diabetes、agegrp、bmi) の観測値は 10,351 件あります。 他の変数はファイル内のデータセットにまだ存在していることに注意してください。 ただし、それらは Stata のメモリにはロードされません。
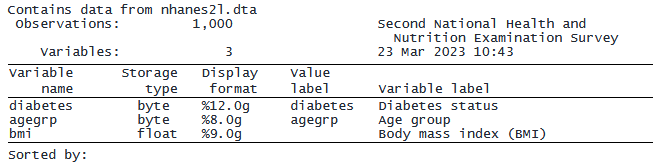
データセットの一部の観測値を使用することもできます。 例えば、データセット内の最初の 1,000 個の観測値のみを使用したいとします。 in オプションを使用するとこれを読込むことができます。 データセットを再度使用する前に Stata のメモリをクリアする clear オプションを含めたことに注意してください。
. use diabetes agegrp bmi using nhanes2l in 1/1000, clear
「describe」と入力すると、メモリ内のデータセットに変数 diabetes、agegrp、bmi の 1,000 件の観測値が含まれていることを確認できます。
. describe
場合によっては、データセット内の変数に基づいて観測を制限したい場合があります。 たとえば、米国北東部地域からの観測に興味があるかもしれません。 変数 region を使用します。
. use region using nhanes2l.dta, clear
次に、変数 region について値ラベルを表示する場合と、非表示にする場合で表にまとめます。
. tabulate region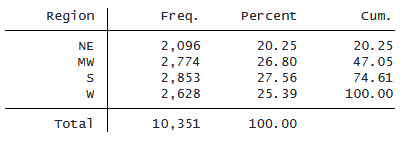
. tabulate region, nolabel
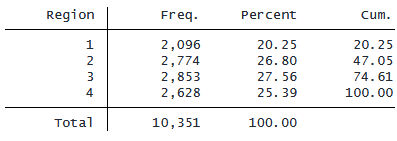
米国北東部地域は「region==1」に対応します。 したがって、オプション ifregion==1 を追加することで、領域 1 の観測値のみを使用してデータセットを開くことができます。
. use region diabetes agegrp bmi using nhanes2l if region==1, clear
「tabulate area」と入力すると、メモリ内のデータセットに region の値が 1 の観測値のみが含まれていることを確認できます。
ファイル内のデータセットには元のデータがすべて含まれていることを忘れないでください。 ただし、Stata のメモリ内のデータセットには、use コマンドで指定した変数と観測値のみが含まれています。 データセットをメモリに保存する場合は、これを覚えておくことが重要です。 変数と観測値のみをメモリに保存し、元のデータファイル内の他のデータは失われます。 データの損失を避けるために、一部を取り出したデータセットは必ず新しい名前で保存してください。
. save nhanes2l_partial.dta
参考
さらに詳しい内容につきましては、下記のマニュアルをご覧ください。

