
因子変数の表記法
因子変数の表記法とは、
回帰モデルを迅速かつ簡単に指定できるようにするためのプレフィクスや演算子のことです。
連続変数と因子変数を区別したり、基準のカテゴリを選択し、変数間の交互作用を指定し、連続変数の多項式を
指定することができます。
また、因子変数の表記法は、regress、probit、logit、
poisson などの Stata の回帰コマンドのほぼすべてで機能します。
まず、データセット nhanes2l を開いてみましょう。
次に、変数 bpsystol、age、bmi、diabetes、hlthstat について確認し、統計量を表示しましょう。
. webuse nhanes2l. describe bpsystol hlthstat diabetes age bmi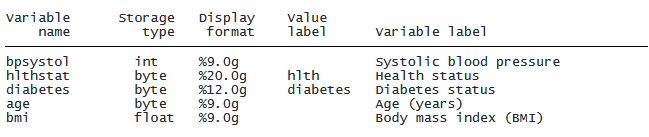
. summarize bpsystol hlthstat diabetes age bmi
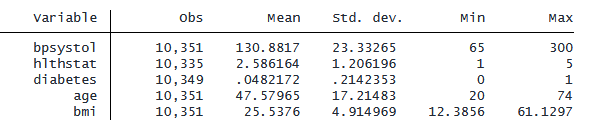
65 ~ 300 mmHg の範囲で収縮期血圧を測定するアウトカム変数 bpsystol に一連の線形回帰モデルを当てはめます。 hlthstat は、健康状態を 1 ~ 5 の範囲で測定します。diabetes は、糖尿病の状態を 0 ~ 1 の範囲で測定します。 age は、年齢であり 20 ~ 74 歳の範囲の値をとります。 また、bmi は、BMIの測定値で 12.4 ~ 61.1 kg/m2 の範囲の値をとります。
カテゴリカル変数における因子変数表記
独立変数 hlthstat を含むモデルから始めましょう。describe コマンドの実行結果で
hlthstat の説明に「hlth」という名前の値ラベルが表示されています。
また、summarize の結果より、最小値が 1 で最大値が 5 であるため、hlthstat はカテゴリ変数であると考えられます。label list コマンドを使用してカテゴリラベルを表示しましょう。
. label list hlth

hlthstat には、Excellent、Very Good、Good、Fair、Poor というラベルの付いた 5 つのカテゴリがあります。 Stata の回帰コマンドは、初期設定では独立変数を連続変数として扱うため、hlthstat のカテゴリごとに ダミー変数を作成する必要があります。 これを手動で行うこともできますが、プレフィクス「i.」を使用する方が簡単です。 プレフィクスは、変数がカテゴリカルであることを Stata に伝えるための因子変数表記法であり、 Stata は一時的なダミー変数を自動的に作成します。 list hlthstat i.hlthstat と入力して、どのように機能するかを見てみましょう。
. list hlthstat i.hlthstat in 1/10
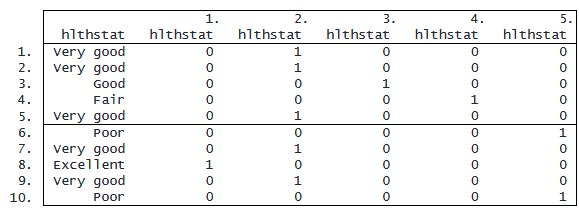
最初の列には、データセット内の最初の 10 個の観測値の hlthstat の値が表示されます。 次の 5 つの 1.hlthstat から 5.hlthstat という名前の列は、Stata が作成した一時的なダミー変数です。 hlthstat のカテゴリ 1 には「Excellent」というラベルが付けられているため、ダミー変数 1.hlthstat は、 hlthstat が「Excellent」に等しい場合は 1 に等しく、それ以外の場合は 0 になります。 hlthstat のカテゴリ 2 には「Very good」というラベルが付けられているため、ダミー変数 2.hlthstat は、 hlthstat が「Very good」の場合は 1 に等しく、それ以外の場合は 0 になります。 ダミー変数 3.hlthstat、4.hlthstat、5.hlthstat は、それぞれ「Good」、「Fair」、「Poor」の同じ パターンに従います。 コマンドの実行終了後、ダミー変数はデータセットに残らないことに注意してください。
以下のように regress コマンドを実行する際にカテゴリカル変数 hlthstat に対して 変数名の頭に「i.」を付して使用します。
. regress bpsystol i.hlthstat
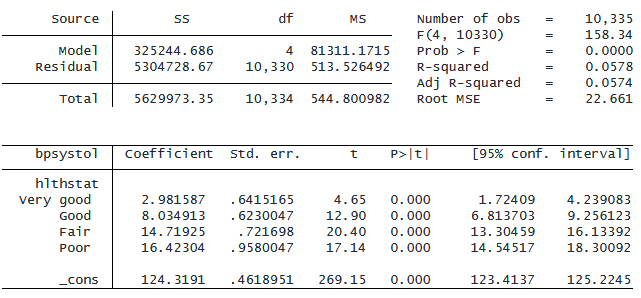
出力結果には、「_cons」というラベルが付いた係数と、 「Very good」、「Good」、「Fair」、「Poor」の各係数が表示れます。 「Excellent」カテゴリはモデルから自動的に削除され、「参照カテゴリ」と呼ばれる比較グループとして使用されました。 初期設定では、Stata は最小の数値を持つカテゴリを選択し、そのカテゴリの結果の平均を推定し、 それに「_cons」というラベルを付けます。 したがって、「Excellent」カテゴリーの平均収縮期血圧は 124.3 mmHg です。 他のカテゴリの係数は、参照カテゴリの平均と各カテゴリの差となります。 たとえば、「Poor」グループの係数は 16.4 であるため、「Poor」グループの平均収縮期血圧は 「Excellent」カテゴリーより 16.4 ポイント高くなります。
「ib(#).」を使用して別の参照カテゴリを選択できます。 「#」は参照カテゴリのカテゴリ番号です。 hlthstat のカテゴリ 5「Poor」を参照カテゴリとして使用してみましょう。
. regress bpsystol ib(5).hlthstat
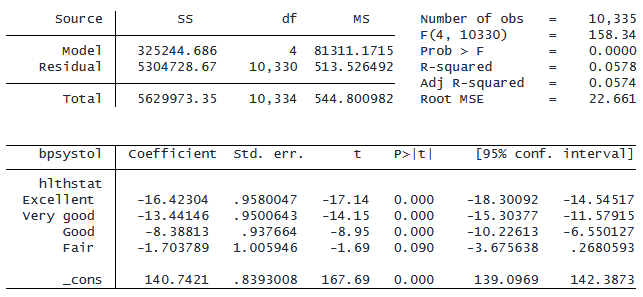
「Poor」カテゴリが出力結果から省略され、「Excellent」が表示されるようになりました。 _cons の係数 140.7 は、「Poor」グループの平均収縮期血圧となり、 「Excellent」グループの平均収縮期血圧は「Poor」グループより 16.4 mmHg 低くなります。
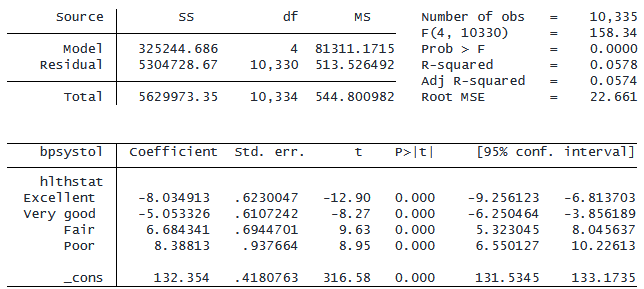
プレフィクス「ib(frequent).」を使用して、サンプルサイズが最大のカテゴリを参照カテゴリとして選択します。
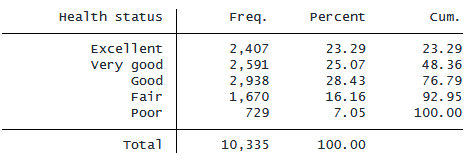
tabulate hlthstat コマンドを実行すると、「Good」カテゴリのサンプルサイズが
最大であることを確認できます。
. tabulate hlthstat
. regress bpsystol ib(frequent).hlthstat
プレフィクス「ib(none)」を使用することで、参照カテゴリを省略します。 noconstant オプションと組み合わせた場合、各カテゴリの平均が係数として表示されます。
. regress bpsystol ib(none).hlthstat, noconstant
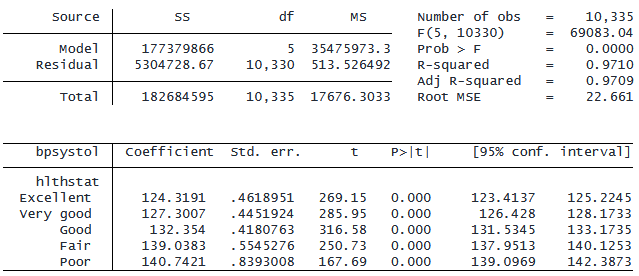
出力結果から、「Excellent」カテゴリーの平均収縮期血圧は 124.3、 「Poor」グループの平均収縮期血圧は 140.7 であることがわかります。
バイナリ変数の因子変数表記法
バイナリ変数は 2 つのカテゴリを持つシンプルなカテゴリ変数であるため、
上で説明した内容はバイナリ変数にも当てはまります。
バイナリ変数は「0/1」ダミー変数としてコード化されることがよくありますが、それでも「i.」を使用する必要があります。
回帰モデルを近似した後に margins などの推定後コマンドを使用する場合は、
プレフィクスを付けます。 いくつかの簡単な例を見てみましょう。
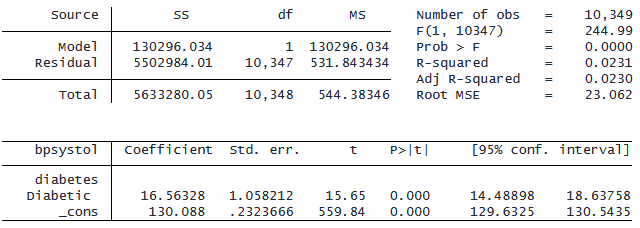
これは、バイナリの独立変数として変数 diabetes を含むモデルです。
. regress bpsystol i.diabetes
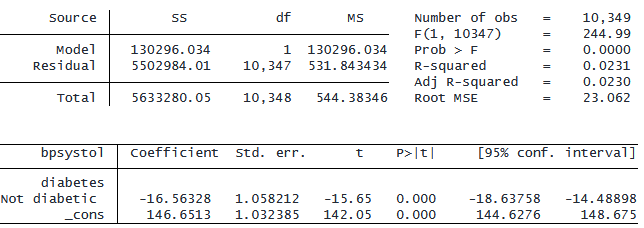
因子変数表記を使用して、糖尿病患者を参照カテゴリーとして選択してみましょう。
. regress bpsystol ib(1).diabetes
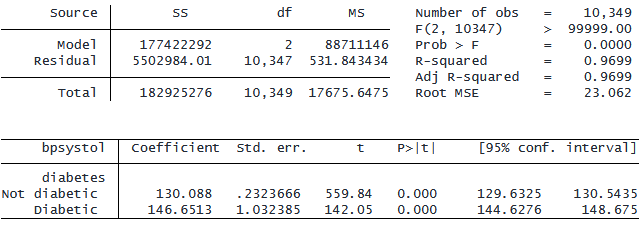
切片も参照カテゴリも持たないモデルを当てはめてみましょう。
. regress bpsystol ib(none).diabetes, noconstant
連続変数の因子変数表記法
Stata の回帰コマンドは、初期設定で独立変数を連続変数として扱います。
一方で、プレフィクス「c.」を使用して明示的に指定することもできます。
独立変数を連続変数として扱う必要があることを Stata に明示的に伝える場合にこのプレフィクスを用います。
これは、他の変数との相互作用に連続変数を含める場合にも必要になります。
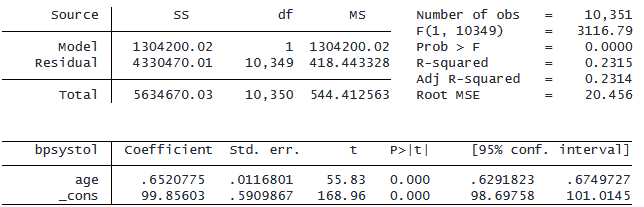
以下は、変数 age を連続な独立変数として扱う例です。
. regress bpsystol c.age
交互作用の因子変数表記法
「#」演算子は 2 つの変数間の交互作用を指定し、「##」演算子は 2 つの変数の主効果と交互作用の両方を指定します。
変数 hlthstat と diabetes の主効果を含むモデルを当てはめて、 「#」演算子を使用してそれらの交互作用を含めてみましょう。
. regress bpsystol i.hlthstat i.diabetes i.hlthstat#i.diabetes
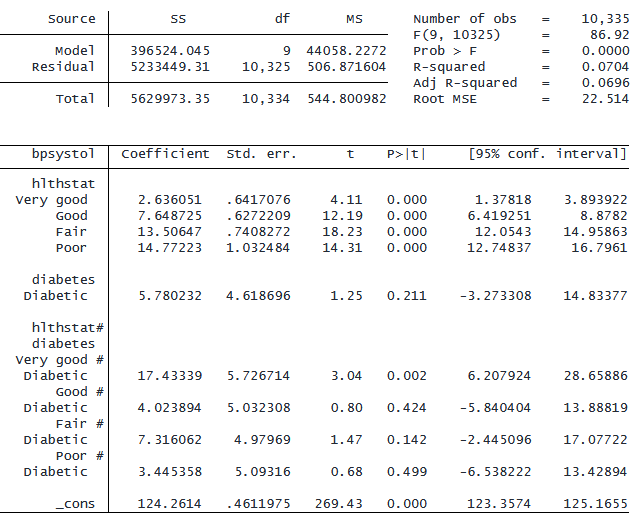
「##」演算子を使用して同じモデルを表現することができます。
. regress bpsystol i.hlthstat##i.diabetes
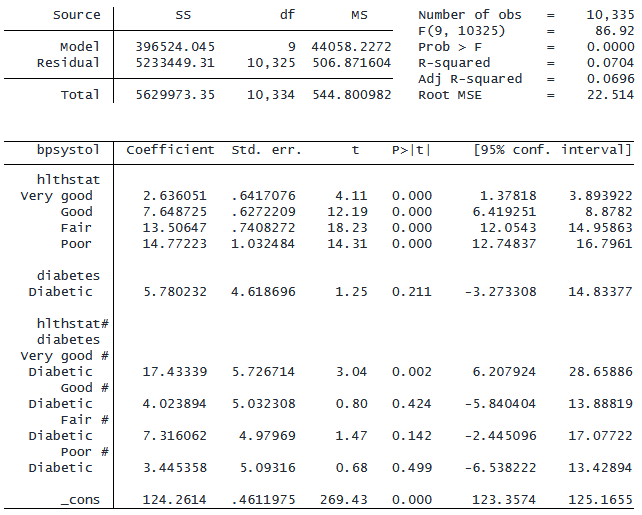
連続変数を含む相互作用を表現することもできます。
. regress bpsystol i.diabetes##c.age
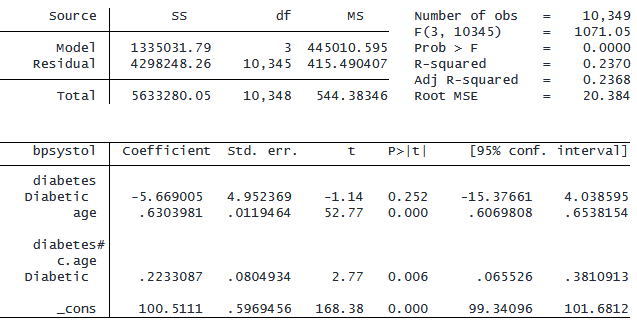
「#」および「##」演算子を使用して、3 変数間および高次の相互作用を含めることもできます。
. regress bpsystol i.hlthstat##i.diabetes##c.age
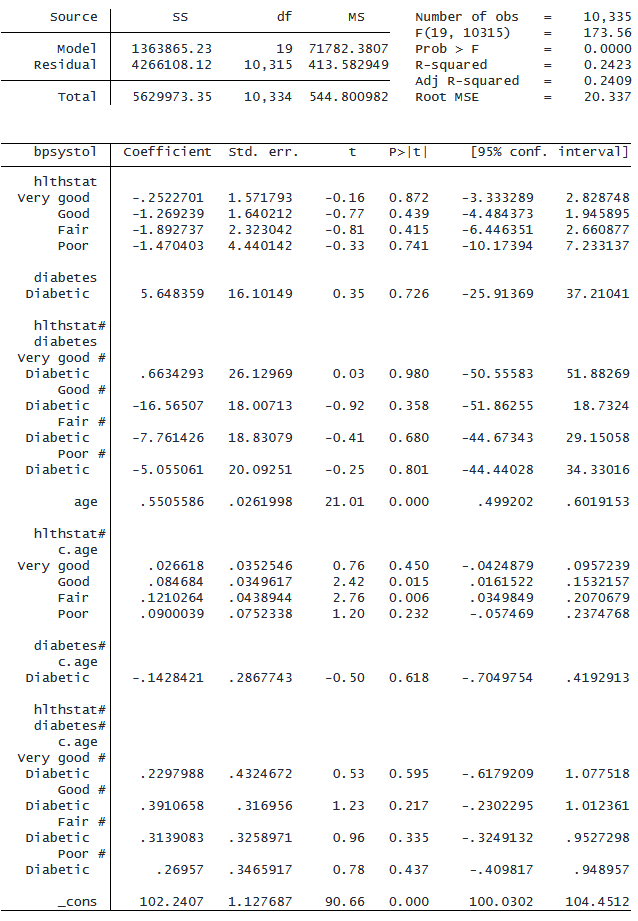
Stata は初期設定で独立変数を連続変数として扱うことをすでに学習しました。 しかし、相互作用演算子の場合はその逆です。 プレフィクスを指定しない場合、 「#」と「##」はどちらも変数をカテゴリカル変数として扱います。 したがって、「hlthstat##diabetes」と入力すると機能します。 ただし、diadiadia##age と入力すると初期設定では age がカテゴリ変数として扱われるため、混乱が生じます。 間違いを避けるために「i.」や「c.」を付けて明示的に表現してください。
プレフィクスは、括弧と一緒に使用すると分配法則が適用されます。 以下の構文は、hlthstat と diabetes をカテゴリカルな独立変数として扱い、 それらの主効果と age との交互作用を含むモデルに適合します。 このモデルには hlthstat と diabetes の交互作用が含まれていないことに注意してください。
. regress bpsystol i.(hlthstat diabetes)##c.age
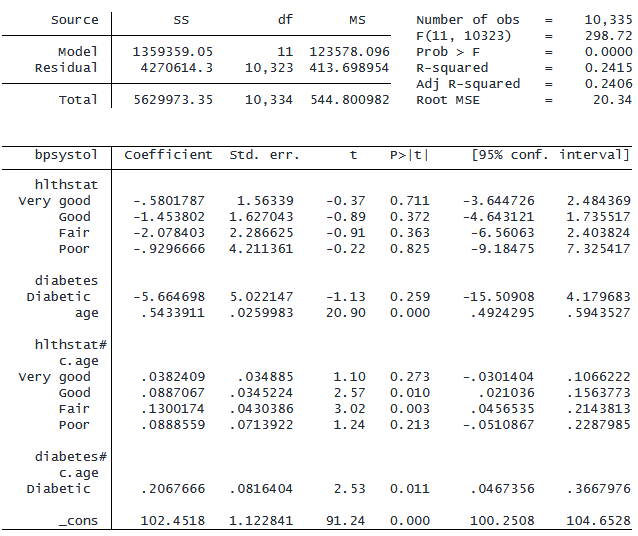
多項式の因子変数表記法
「#」および「##」演算子を使用して、連続変数の多項式項を指定することもできます。 たとえば、モデルに age と age の 2 乗の両方を含むモデルを当てはめたい場合があります。 これは、age とそれ自体を相互作用させることで実現できます。
. regress bpsystol c.age##c.age
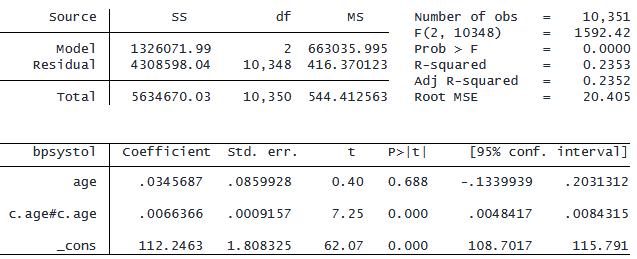
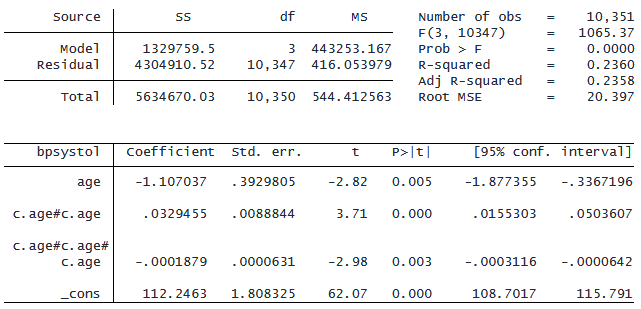
age の 3 乗を表す用語を含めることもできます。
. regress bpsystol c.age##c.age##c.age
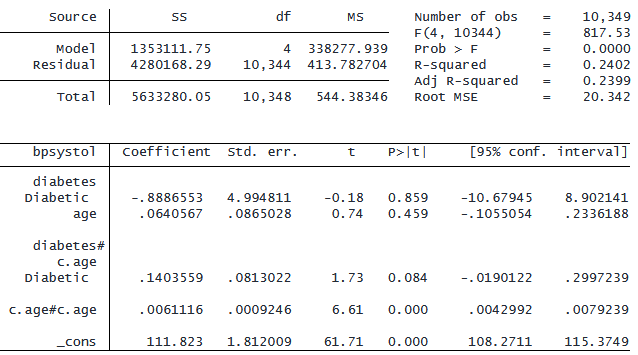
age と別の変数の相互作用を含める場合で、age の 2 乗を含めることもできます。
. regress bpsystol i.diabetes##c.age c.age#c.age
因子変数の表記法について詳しくは、Stata ドキュメントを参照してください。
参考
さらに詳しい内容につきましては、下記のマニュアルをご覧ください。

