
GAUSS™ 25 新機能
GAUSS 25はデータ探索、高度な分析、シームレスなモデル比較のための直感的なツールでワークフローに変革を起こします。
包括的なパネルデータツール
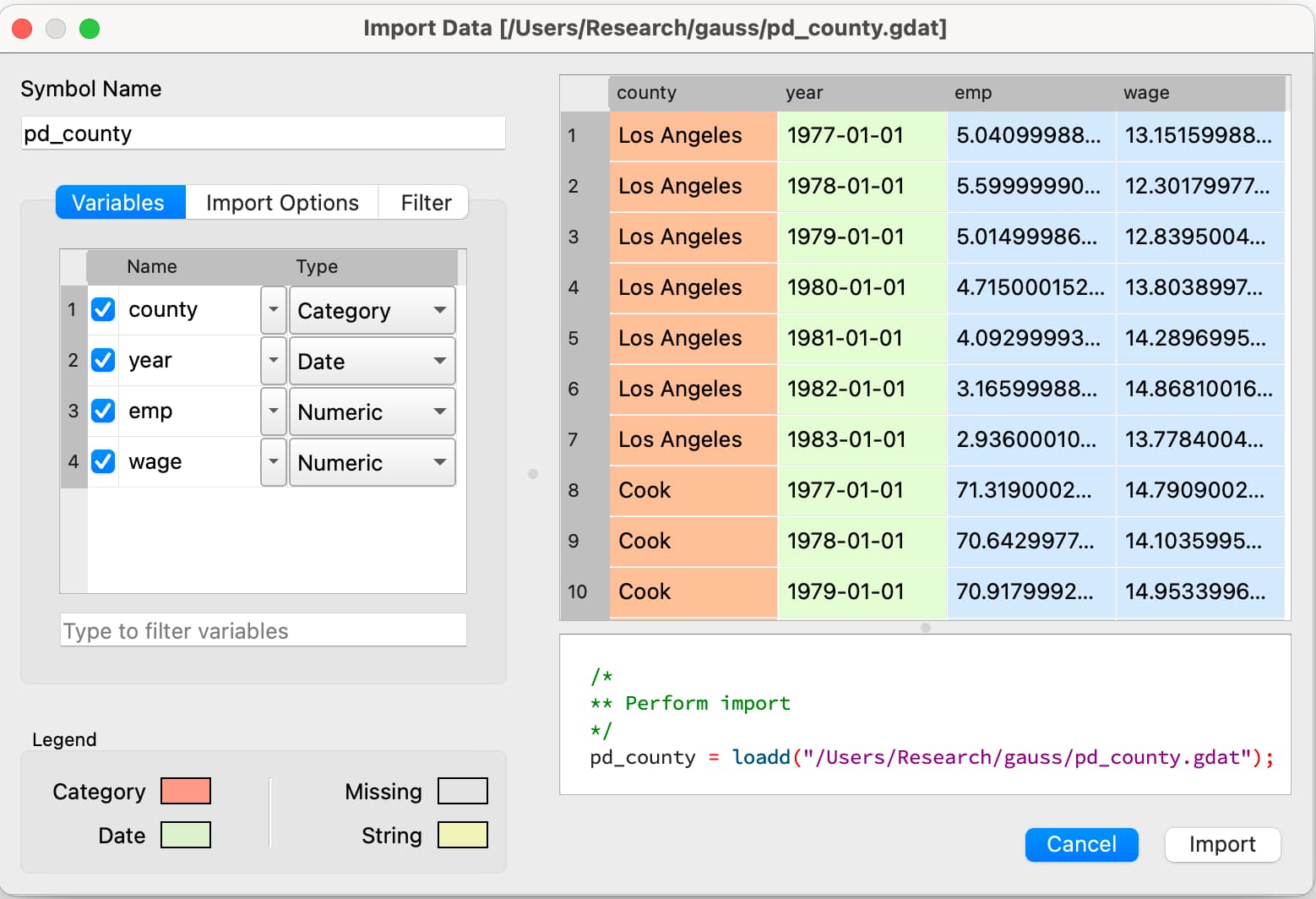
パネルデータを理解するのに苦労していませんか? GAUSS 25ではデータの読み込み、分析、探索の方法を変革し、分析者が必要とする直感的なツールを用意しました。
パネルデータの特性を調べる
- pdSummaryを使用して、全体、グループ内、グループ間の要約統計を調べます。
// データのインポート pd_cty = "pd_county.gdat"); /* ** パネルデータの要約レポートを作成する ** pdSummaryは自動的にグループ変数と時間変数を検出する */call (pd_cty);
======================================================================================
Group ID: county Balanced: Yes
Valid cases: 28 Missings: 0
N. Groups: 4 T. Average: 7.000
======================================================================================
Variable Measure Mean Std. Dev. Minimum Maximum
--------------------------------------------------------------------------------------
emp Overall 30.201 25.514 2.936 73.689
Between . 28.888 4.367 71.362
Within . 1.376 26.728 32.528
wage Overall 17.313 4.273 12.302 28.908
Between . 4.394 13.576 23.630
Within . 1.802 14.377 22.591
======================================================================================
- pdSizeとpdTimeSpansを使用してパネルデータの時間分布を確認します。
// パネル内の各個体のサイズと範囲に関するレポートを表示するcall (pd_cty);
============================================================ Group ID: county Balanced: Yes Valid cases: 28 Missings: 0 N. Groups: 4 T. Average: 7.000 ============================================================ county T[i] Start Date End Date ------------------------------------------------------------ Cook 7 1977-01-01 1983-01-01 Harris 7 1977-01-01 1983-01-01 Los Angeles 7 1977-01-01 1983-01-01 Maricopa 7 1977-01-01 1983-01-01 ============================================================
モデリングのためのパネルデータの準備
- シームレスなワークフローを実現するために、グループと時間の変数を自動かつインテリジェントに検出します。
- pdSortを使用して、検出されたグループと時間変数でパネルデータを即座に並べ替えます。
- 新しいpdLagとpdDiffを使用してパネルデータのラグと階差を計算します。
// パネル内の各個人の2番目のラグを計算するpd_cty_l = (pd_cty, 2);// 最初の10個の観測値を出力するprint pd_cty_l[1:10,.];
county year emp wage
Los Angeles 1977-01-01 . .
Los Angeles 1978-01-01 . .
Los Angeles 1979-01-01 5.0409999 13.151600
Los Angeles 1980-01-01 5.5999999 12.301800
Los Angeles 1981-01-01 5.0149999 12.839500
Los Angeles 1982-01-01 4.7150002 13.803900
Los Angeles 1983-01-01 4.0929999 14.289700
Cook 1977-01-01 . .
Cook 1978-01-01 . .
Cook 1979-01-01 71.319000 14.790900
- pdAllBalancedとpdAllConsecutiveを使用してバランスと連続性を確認します。
新しい仮説検定
新しいwaldTestプロシージャは推定後の線形仮説の検定のために強力で直感的なツールを提供します。
- OLS、GLM、GMM、分位点回帰の後に推定後の仮説検定を実施
- 変数名を使用して簡単に仮説を指定
- 仮説における変数の線形結合の包括的なサポート
// olsモデルを実行 struct olsmtout cen_ols; cen_ols ("census3.dta", "brate ~ medage + medage*medage + region"); // NCentral地域とSouth地域の係数が等しいという仮説を検定する{ wald_stat, p_value } = (cen_ols, "region: NCentral - region: South");
====================================== Wald test of null joint hypothesis: region: NCentral - region: South = 0 ------------------------------------- F( 1, 44 ): 5.0642 Prob > F : 0.0295 =====================================
新しいqfitSlopeTestを使用して、分位数回帰後の分位数間の傾きの等価性をチェックします。
// 回帰のためにtauを設定 tau = 0.35|0.55|0.85; // quantileFitの呼び出し struct qfitOut qOut; qOut = "regsmpl.dta", "ln_wage ~ age + age:age + tenure", tau); // すべての分位点にわたるすべての傾きの結合等価性をテストする(qOut);
===================================
Joint Test of Equality in Slopes :
tau in { 0.35 , 0.55 , 0.85 }
Model: ln_wage ~
age + age_age + tenure
-----------------------------------
F( 9, 28097 ): 138.2428
Prob > F : 0.0000
===================================
改良された結果の表示
GAUSS 25では、すべての推定手順にわたって拡張されたモデル診断と一貫した結果の表示が提供されるようになりました。
// フルパスでファイル名を取得するfile = ("examples/clotting_time.dat");// 推定を実行し、レポートを表示するcall (file, "lot1 ~ ln(plasma)", "gamma");
Generalized Linear Model
===================================================================
Valid cases: 9 Dependent variable: lot1
Degrees of freedom: 7 Distribution gamma
Deviance: 0.0167 Link function: inverse
Pearson Chi-square: 0.0171 AIC: 37.990
Log likelihood: -16 BIC: 38.582
Dispersion: 0 Iterations: 38
Number of vars: 2
===================================================================
Standard Prob
Variable Estimate Error t-value >|t|
-------------------------------------------------------------------
CONSTANT -0.016554 0.00092754 -17.848 4.279e-07
ln(plasma) 0.015343 0.00041496 36.975 2.7511e-09
===================================================================
これらの改良により、これまでよりも簡単にモデルの比較、結果の探索、自信を持ったより深い洞察を得ることができるようになっています。
パフォーマンスと速度の向上
- 拡張された2元配置の表機能があるtabulateを使用して、行または列のパーセンテージを求めます。
- gmmFitIV関数は変数名を特定し報告するためにデータフレームのメタデータを使用するようになり、「by 」キーワードをサポートしました。
- ソートされたデータをオプションで指定することで、countsを使用する際のスピードが向上します。
- plotFreqプロシージャはグループ間の度数をカウントするための「by 」キーワードをサポートしました。
// データセットのロード tips2 = ("tips2.csv"); // 喫煙者のカテゴリー(「はい」「いいえ」)ごとに、1日あたりの来店頻度をプロットする。 (tips2, "day + by(smoker)");
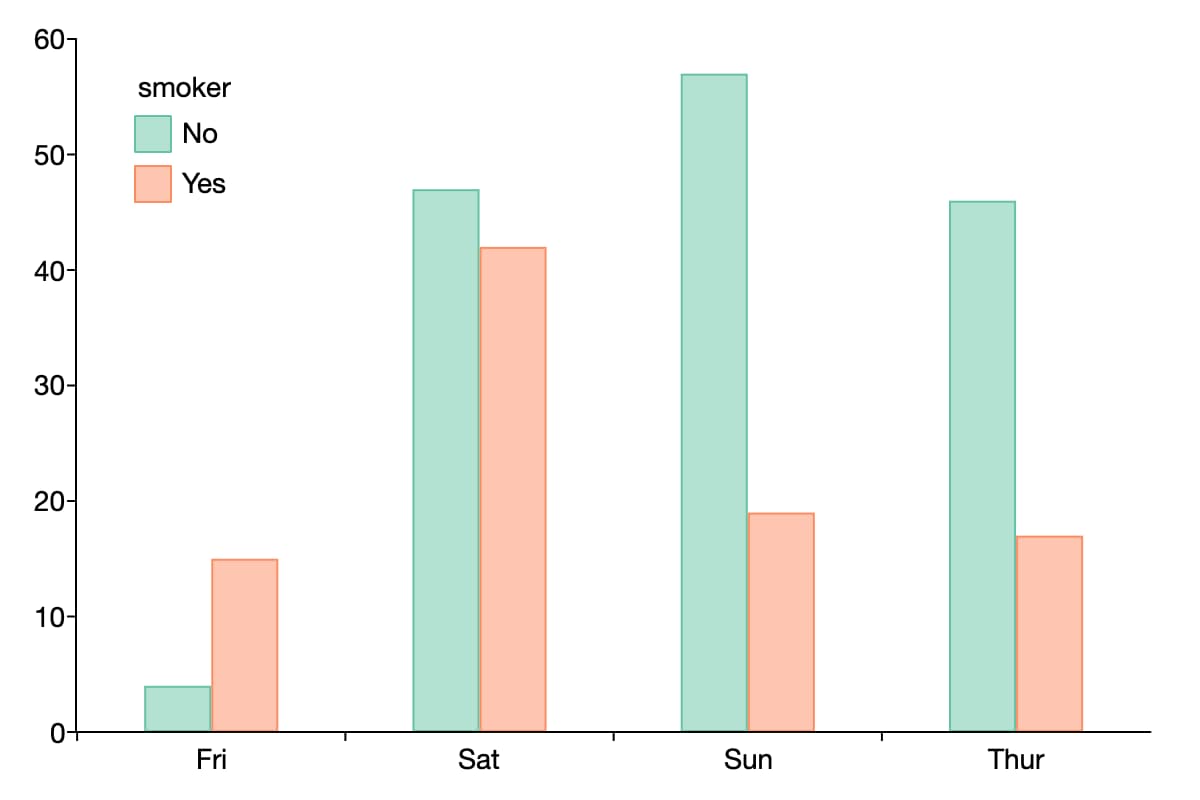
- savedは、Excelファイルのラベルを使用して、カテゴリ変数と文字列変数を自動的に検出して保存するようになりました。
その他バグ修正など完全な更新内容は開発元のページをご覧ください。

