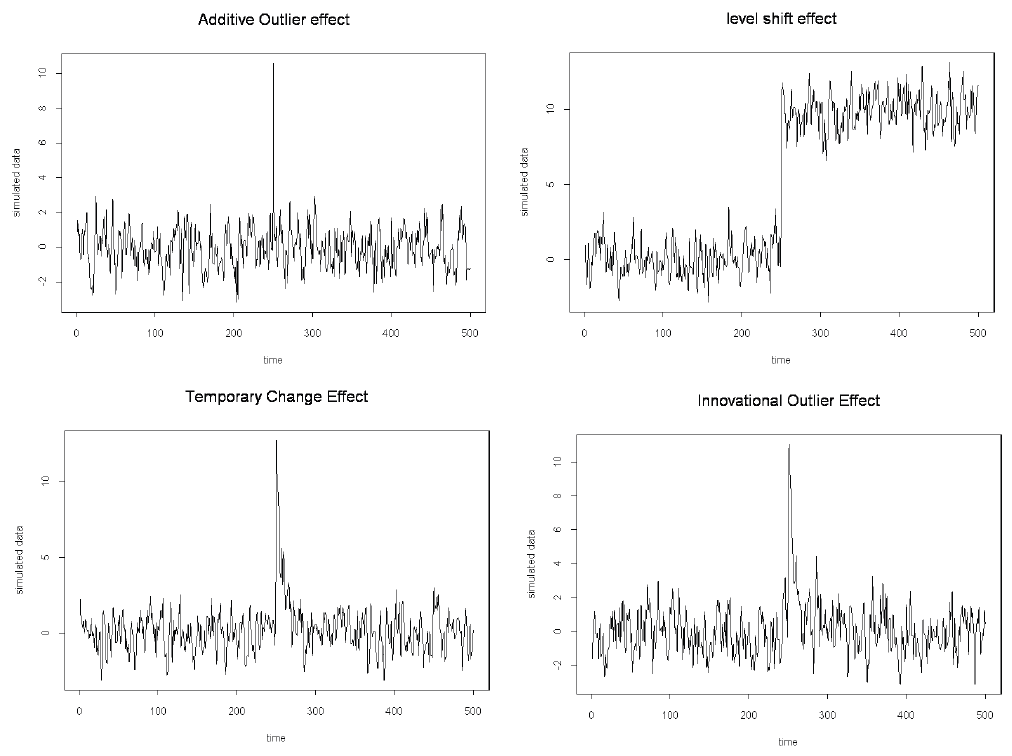
EViews 14は、シリーズ内の外れ値または推定式の残差を特定するための新しく、使いやすいツールを提供します

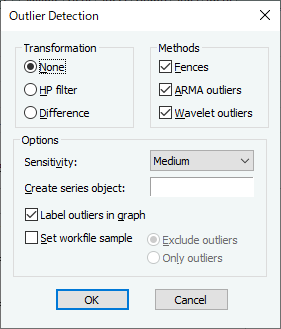
シリーズ名.outlier
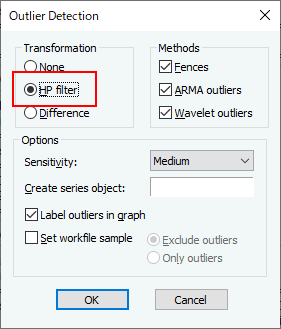
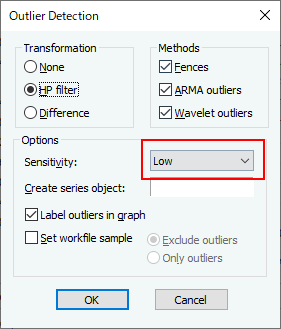
| Low | Medium | High | |
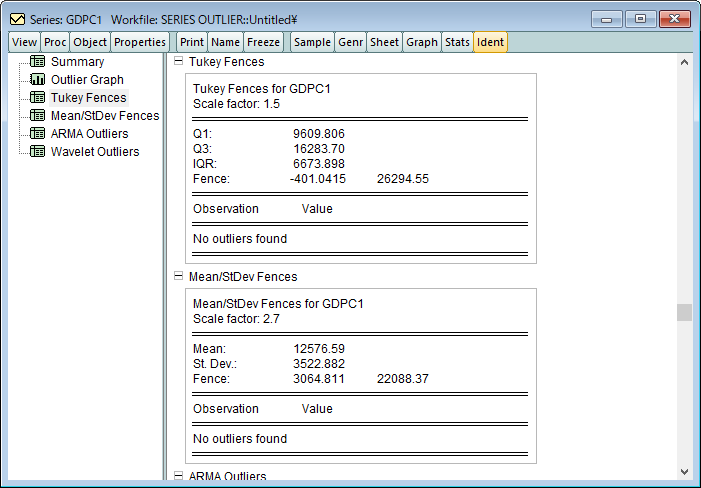
| Tukey $m$ | 3.0 | 1.5 | 0.4 |
| 平均・標準偏差 $m$ | 4.7 | 2.7 | 1.5 |
| ARMA $c$ | 16.0 | 8.0 | 4.0 |
| ウェーブレット FDR | 0.0005 | 0.001 | 0.01 |
C:\Program Files\EViews 14\Example Files\EV14 Manual Data\Chapter 11 - Series\series outlier.wf1
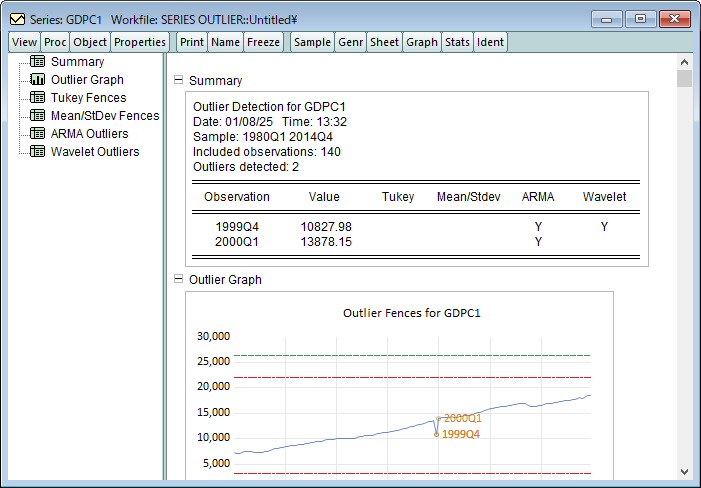


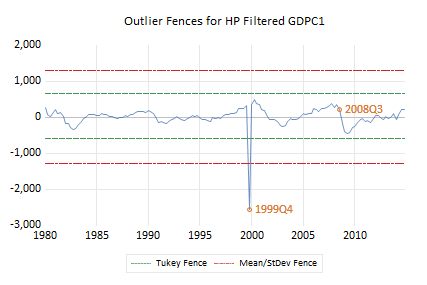


C:\Program Files\EViews 14\Example Files\EV14 Manual Data\Chapter 26 - Specification and Diagnostic Tests



ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2025 Lightstone Corp. All Rights Reserved
