

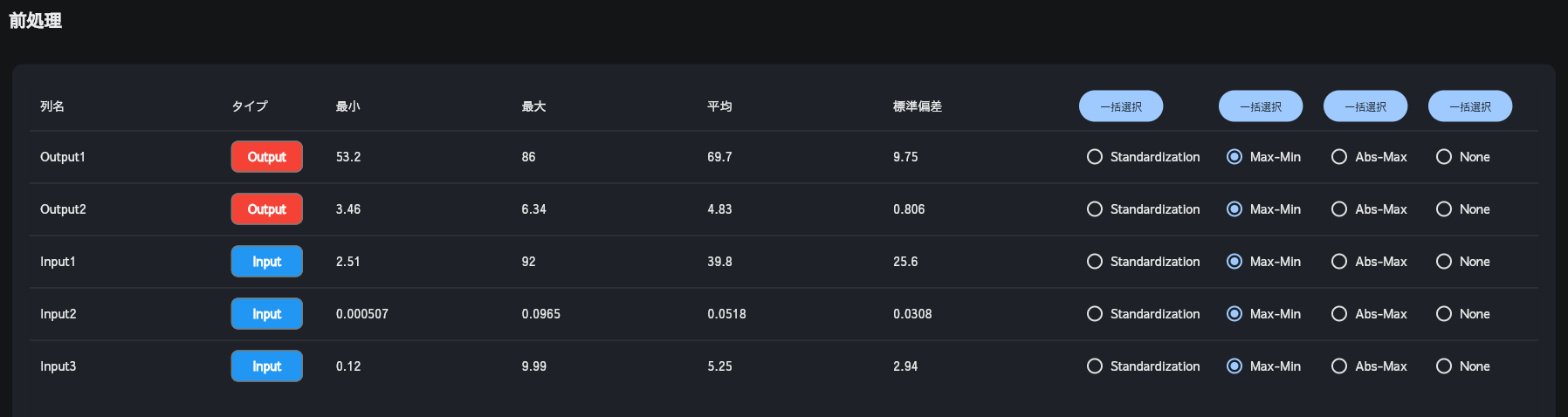
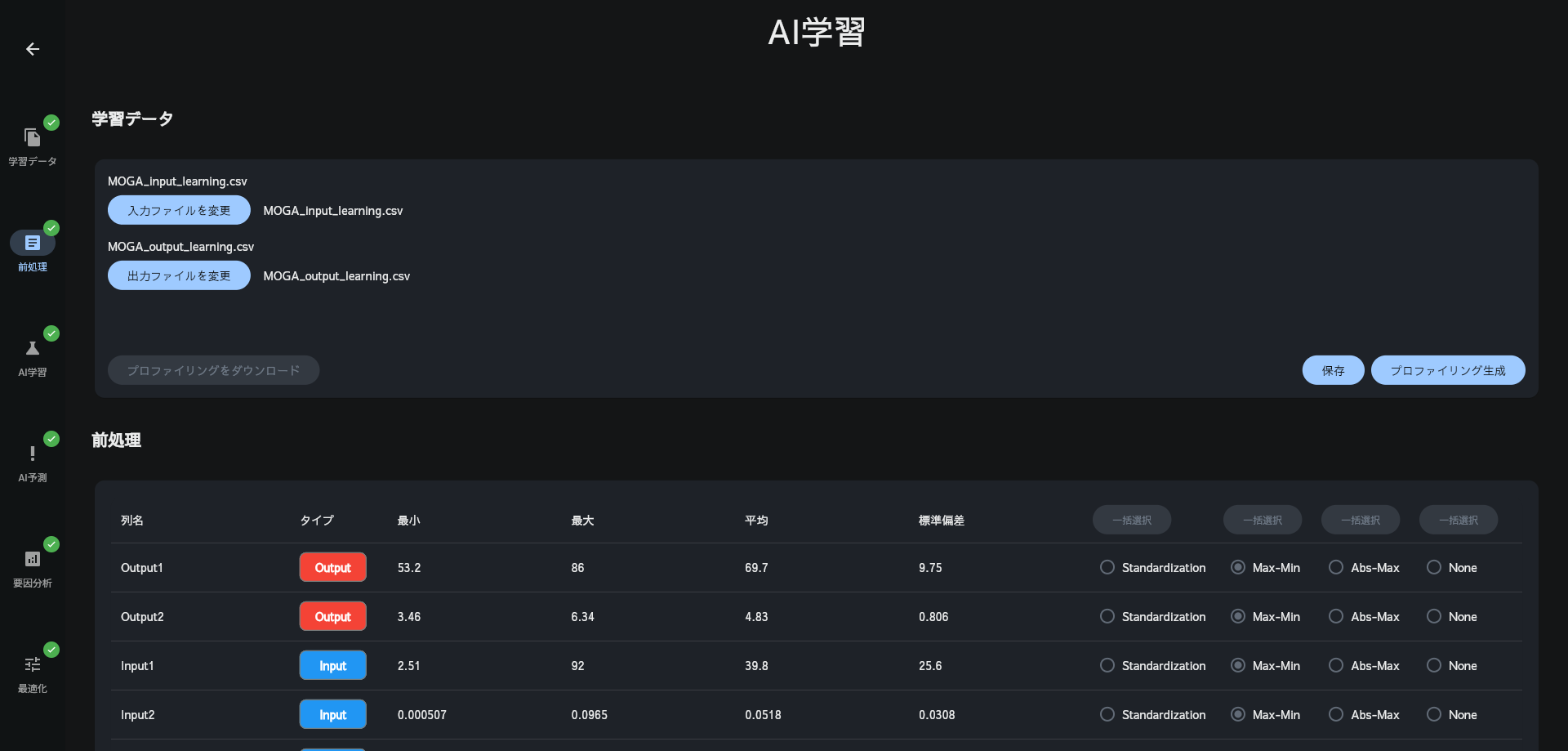
AIの予測精度を上げるためには、データを適切に前処理する必要があります。Multi-Sigmaにデータをアップロードすると、適切な前処理方法が自動で選択されます。データに欠損値がある場合でもMulti-Sigma上で補完できます。
多くのAIツールでは目的変数を1つしか取ることができません。Multi-Sigmaは複数の目的変数に対応しており、「高性能化 & コスト削減」のように複数の目的を同時に達成するための条件を知りたい場合に最適です。
深層学習を使った解析は、学習時の条件(ハイパーパラメータ)を適切にチューニングしなければ高い予測精度を得られません。Multi-Sigmaは独自のオートチューニング機能を搭載しており、小規模な実験データに対しても最適なハイパーパラメータを自動で探索し、過学習に陥ることなく高精度に予測します。オートチューニングの所用時間は約1時間です。

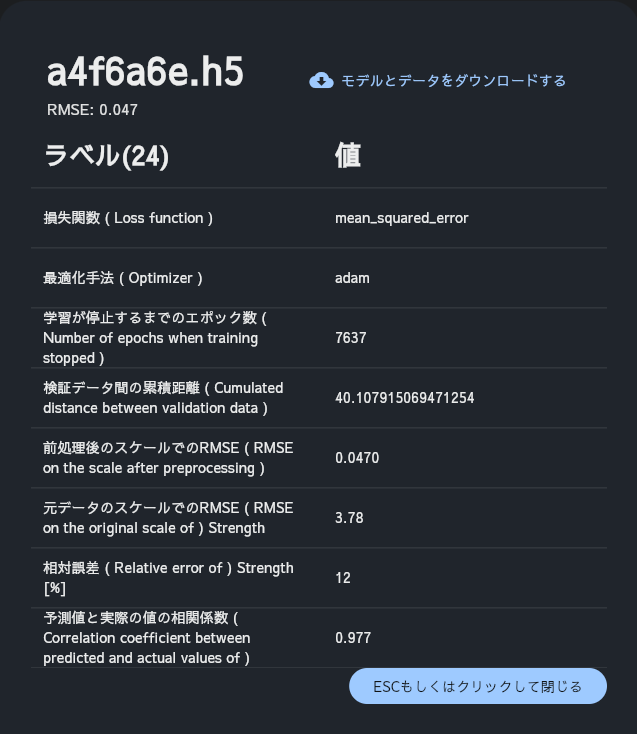
各AIモデルのハイパーパラメータの値や各アウトプットに対する相対誤差、予測値と実測値の相関係数等を確認できます。これらの情報とともにAIモデルをダウンロードできます。モデルはH5形式のファイルで、PythonのKeras/Tensorflowのフレームワークで利用できます。
ニューラルネットワーク解析ではアンサンブルモデルを使用できます。複数のAIモデルを組み合わせ、その平均値を用いて解析(予測・要因分析・最適化)を行います。特にデータの数が少ない場合は、アンサンブルモデルを用いることで予測精度の向上が期待できます。

1つまたは複数のAIモデルを組み合わせた際の応答を2D折れ線図/3D曲面図で表します。グラフの表示はワンクリックで切り替えできます。

AI学習によって作成されたAIモデルを用いて、未知のインプットデータに対するアウトプットデータの予測を行います。
検証用データ(AI学習に使用していないインプット・アウトプットのデータ)を用いて予測を行うと、予測値と実測値の誤差が算出されます。予測結果はCSVファイルとしてダウンロードできます。

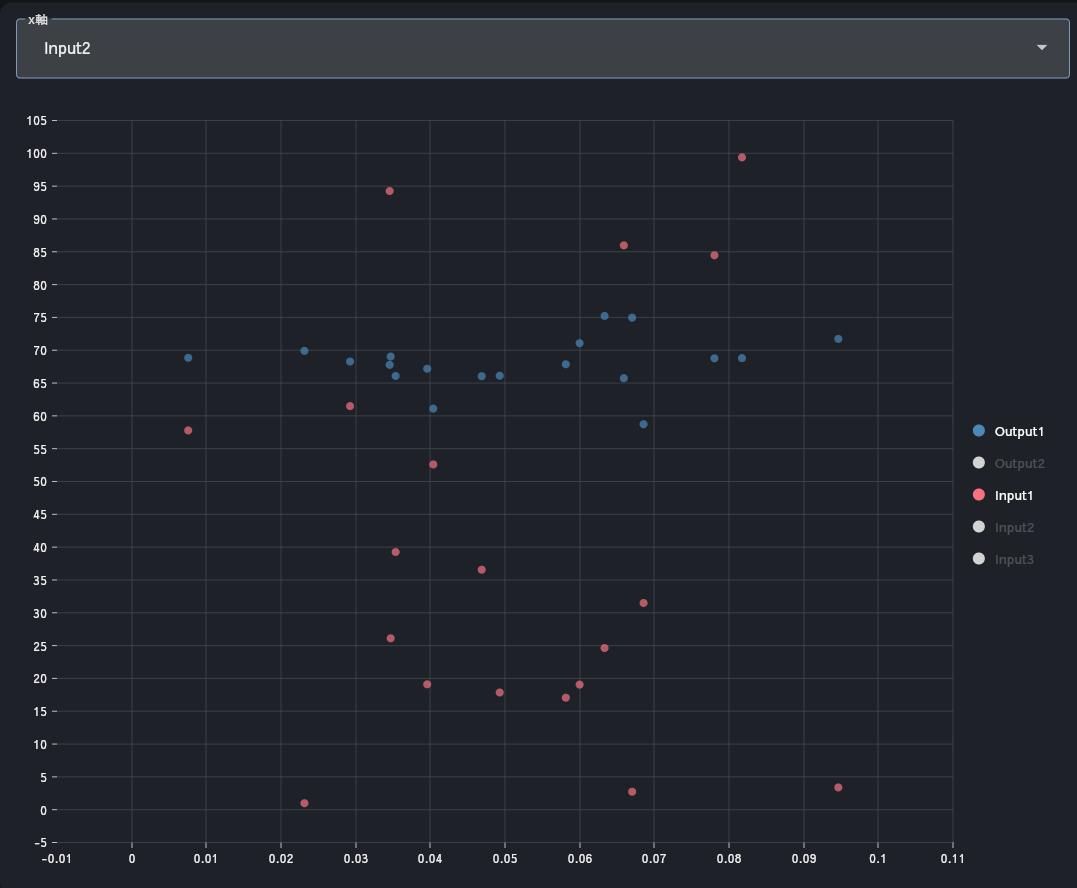
予測値と実測値のプロットを表示します。X/Y軸に表示するデータはワンクリックで切り替えできます。
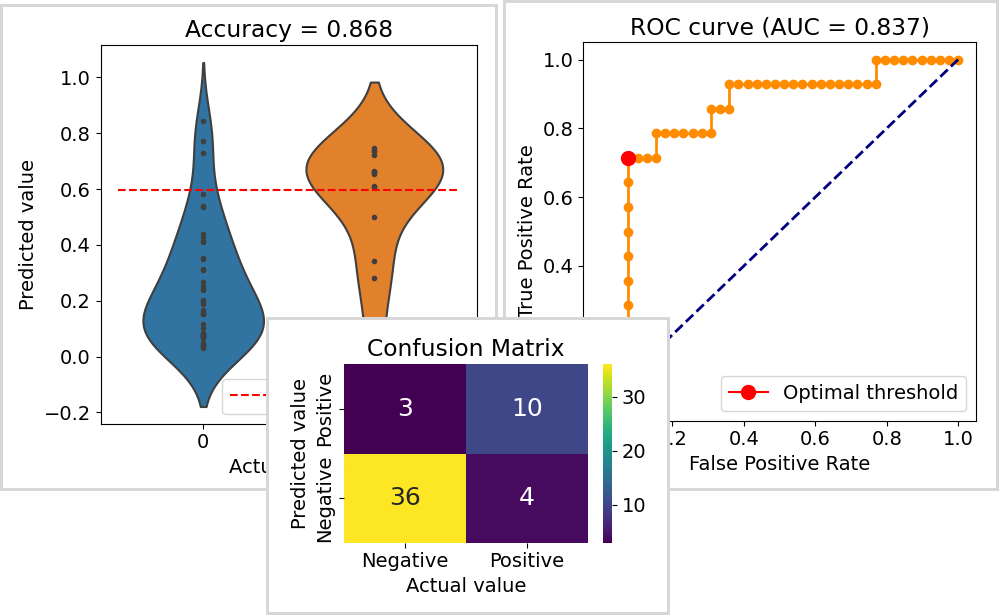
アウトプットが2値データの場合は、予測・検証結果をROC曲線や混同行列で表します。
作成したAIモデルにおいて、各インプットが各アウトプットにどの程度影響を与えているかを定量的に評価します。
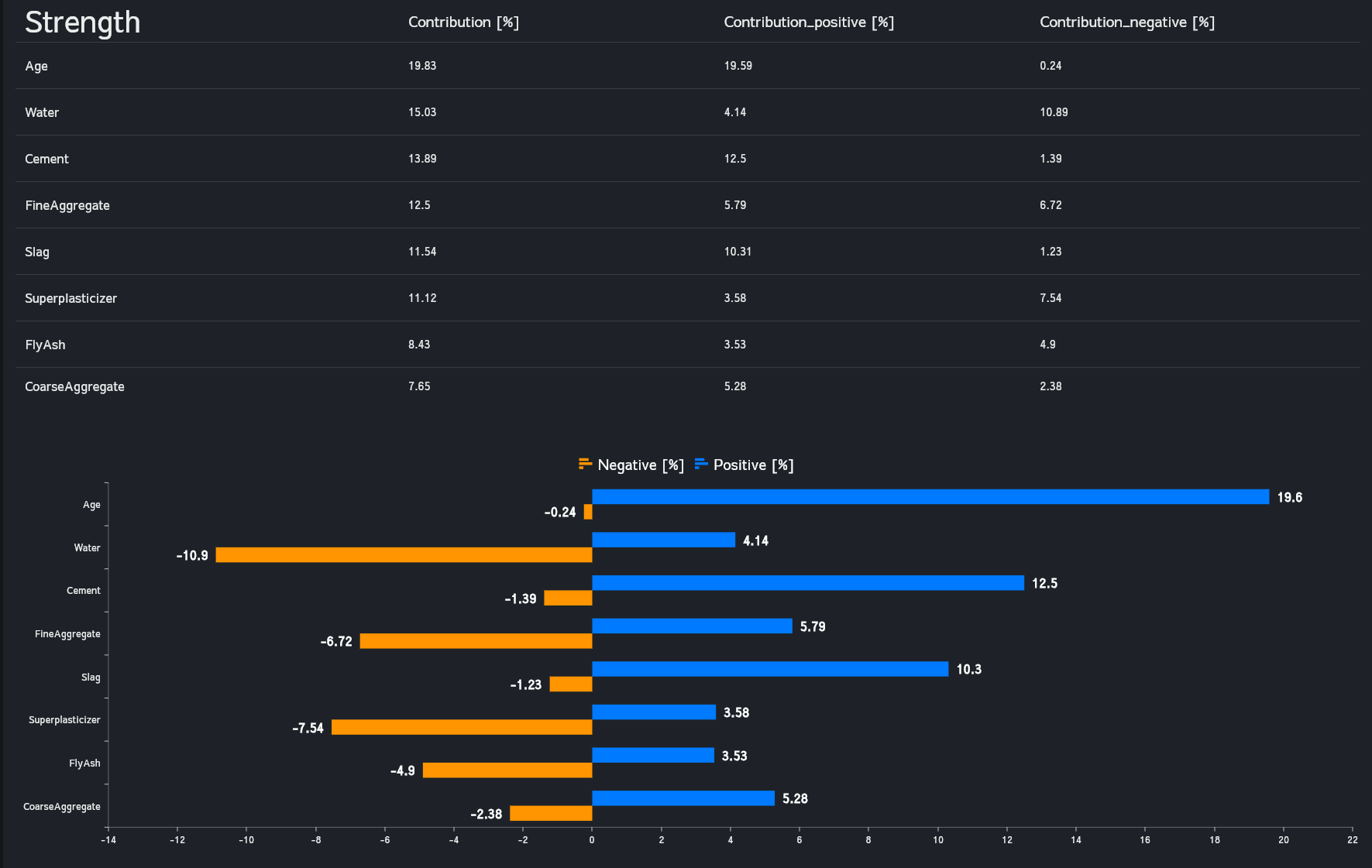
各アウトプットに対する各インプットの正負の影響を表とグラフで表示します。寄与度の正負/大きさは各インプットの数値範囲により変化します。
学習データから算出される最大値・最小値の範囲から一律に一様分布に従ってデータ点を1万点サンプリングし、それらをインプットとして、AIモデルからアウトプットを得ます。その結果からアウトプットが取り得る範囲の確認や、アウトプット間の傾向を見ることが可能です。

作成したAIモデルと多目的遺伝的アルゴリズムを用いて、最適なアウトプットとなるインプット条件の探索を行います。トレードオフの関係にある複数のアウトプットに対しても最適解の集合を取得できます。
アウトプットに対して
インプットに対して
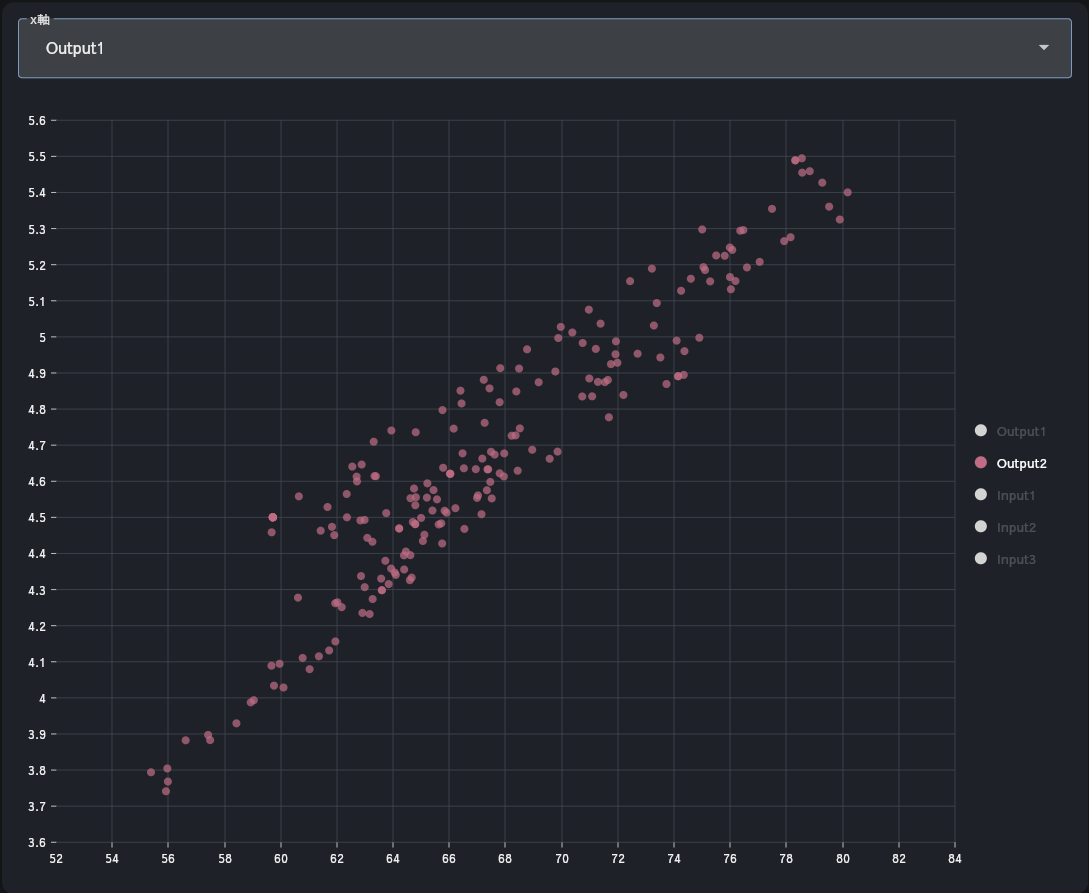
最適化結果のデータ(様々なインプット条件での最適解の集合)を2D/3D散布図で表します。グラフの表示はワンクリックで切り替えできます。3D散布図はアニメーション表示も可能です。
研究の初期に、次に行うべき実験の条件を探索します。データ数3~5程度から解析できます。得られた条件で実験を行い、そのデータを追加してさらに解析するというサイクルを繰り返して精度を高めます。
ガウス過程を仮定して、獲得関数の数値が高い領域を探索します。学習の所要時間は数秒~数十秒です。
ニューラルネットワーク解析と同様です。
作成したAIモデルとベイズ最適化を用いて、最適なアウトプットとなるインプット条件の探索を行います。ベイズ最適化では、データが疎な領域に対して不確実性(分散)を考慮して評価します。
アウトプットに対して
インプットに対して
複数の工程を経て最終製品が作られるような場面で役立つ機能です。各工程のデータでAIを作成し、それらを組み合わせて解析を行います。これにより、最終製品で目的の性能等を得るために、どの工程をどのような条件で行えばよいのかが分かります。
上から順番にボタンを押していくだけ!プログラミング不要で誰にでも使いやすい!
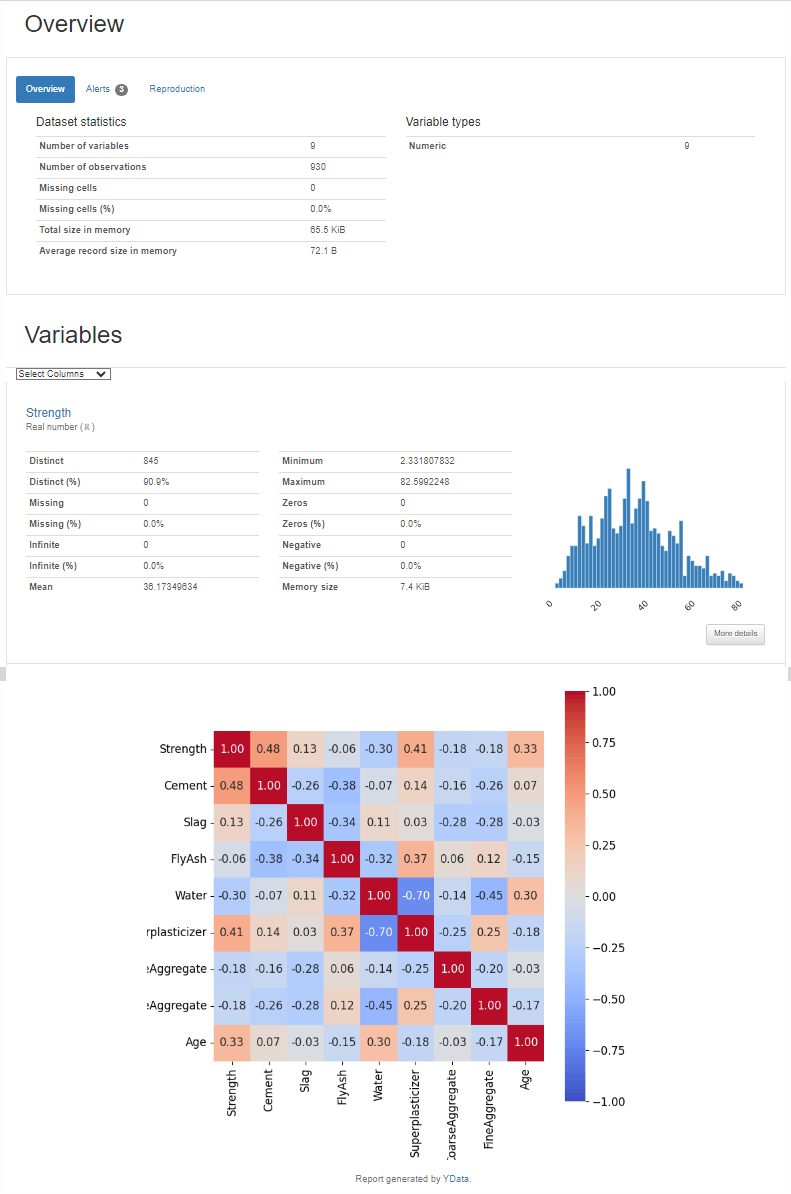
アップロードしたデータの統計解析を行い、結果を図表で表示します。データの傾向や相関を把握するのに便利です。
データ数とインプット数、各インプットの値の範囲を指定して、簡易的な実験データを生成します。これをAI予測の入力データとして用いると、各インプットの制約下において各アウトプットが取りうる値の範囲と、それを形成する条件の組み合わせを大まかに把握できます。手持ちのデータのばらつきが大きい場合や、シミュレーションで全体像を把握したい場合に便利な機能です。

Multi-Sigmaで作成したAIをユーザー同士で共有できます。別部署のメンバーや、共同研究者とのデータ共有に便利です。

ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2026 Lightstone Corp. All Rights Reserved