セミナー・ウェビナー開催情報
ラーニングコンテンツ
各商品の操作方法や技術資料等は、各商品ページのラーニングメニュー内にございます。
統計・計量経済
AI解析
科学技術
結晶構造
質的研究
画像解析
ライブラリ
お電話でのお問い合わせ
平日 9:00~18:00
メールでのお問い合わせはこちら
体験版ダウンロード
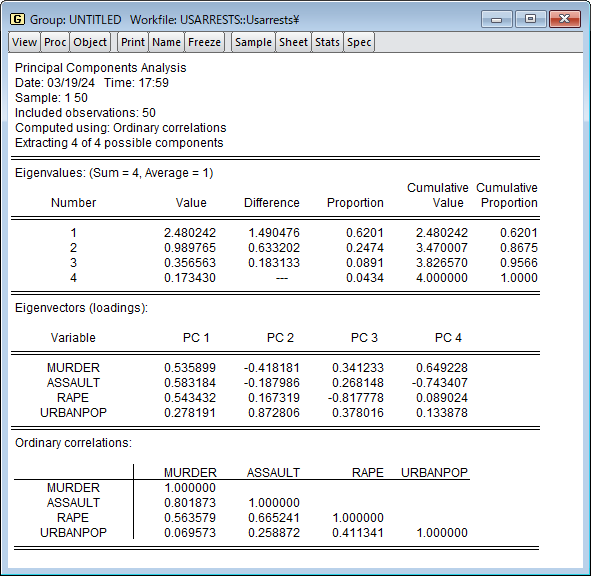
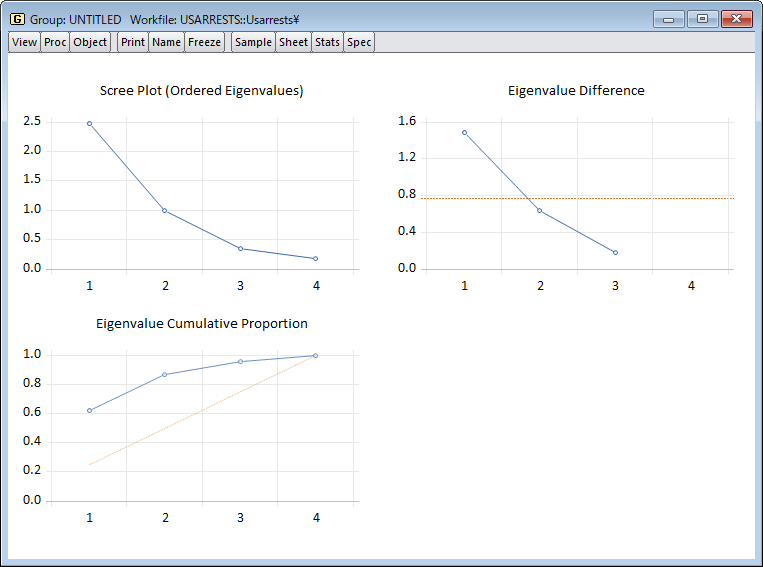
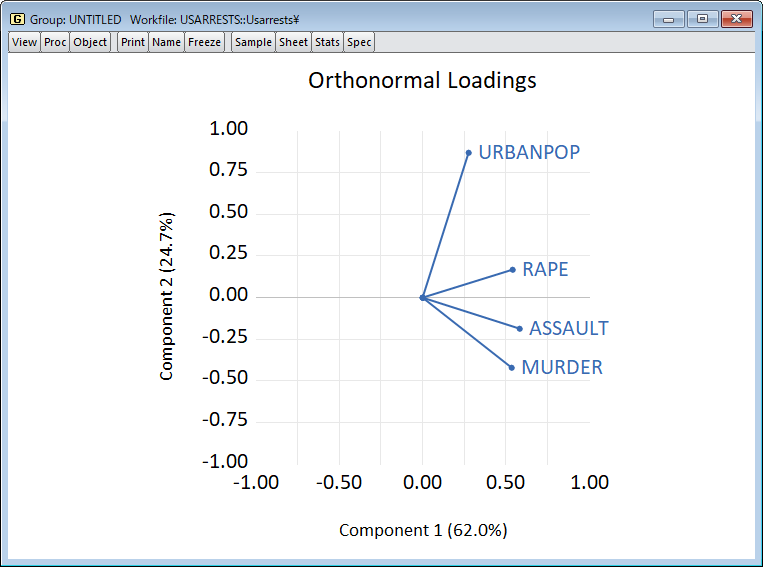
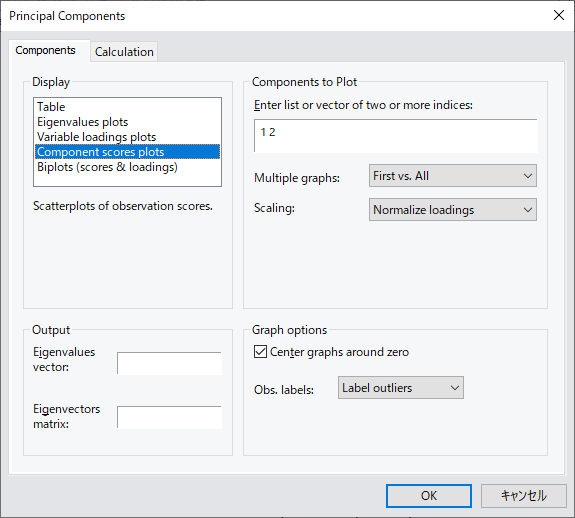
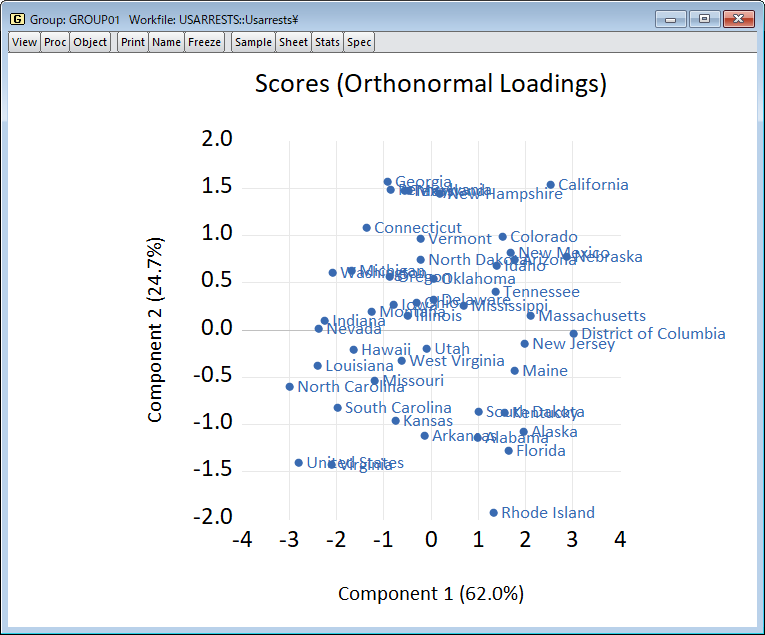
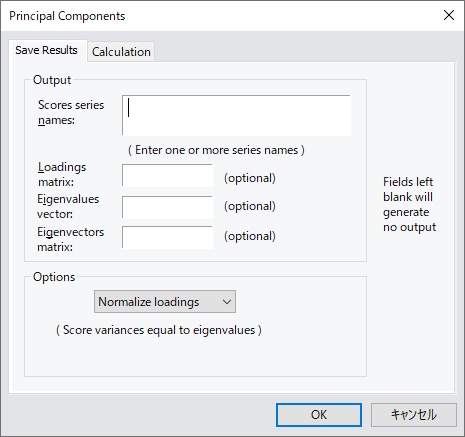
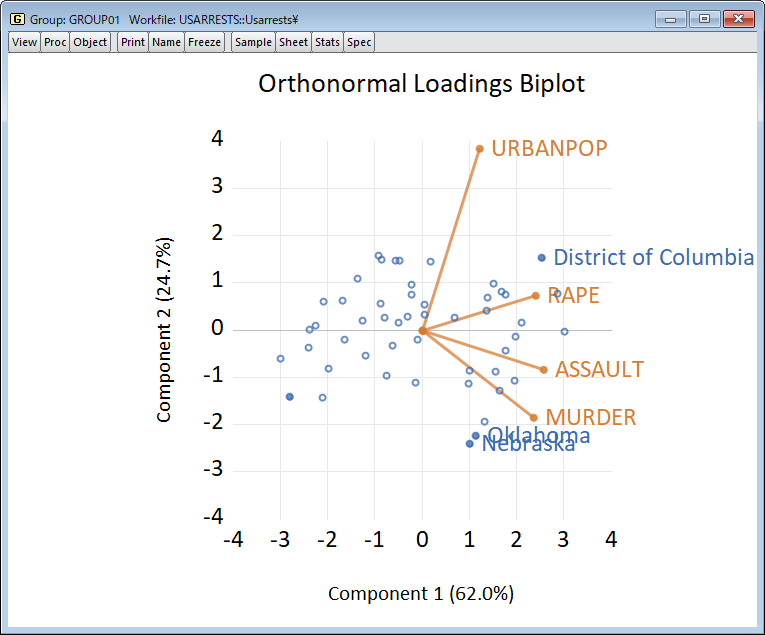
ここでは、EViews を使用した主成分分析を紹介します。 特に、私たちは、その最も重要な特徴を特定し、存在する可能性のある推論的な結論を引き出すために、あるデータセットに PCA を適用したいという願望によって動機付けられています。 このページは、開発元ブログの理論編と実践編を元に作成しています。
サンプルファイルのダウンロード
EViews技術資料集