

ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2024 Lightstone Corp. All Rights Reserved

統計の本を読む前に
読むページ

統計の本を読む前に読むページ
このページでは回帰分析を用いた予測についてご紹介します。
予測は将来の行動や方針を決定するために重要な分析であり、様々な場面で用いられます。
ここでは一例として小麦の収穫量を取り上げます。
小麦の収穫量を高い精度で予測することができれば、将来の生産計画を適切に立てることができます。
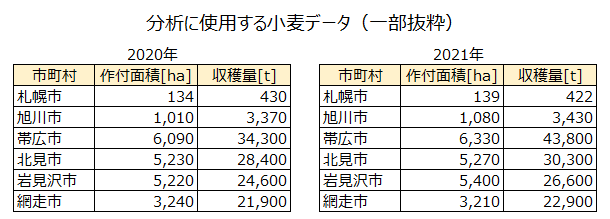
小麦の収穫量 [t] と作付面積 [ha] のデータを使って回帰分析を行います。2020年と2021年の2時点分のデータを使い、2020年のデータで回帰モデルを作成し、2021年の収穫量を予測します。 実際に使用するデータ(一部抜粋)は下記の通りです。
収穫量を予測したいので、収穫量を目的変数として回帰分析を行います。また、説明変数には作付面積を使用します。収穫量を表す式は下記のようになります。
収穫量 = 傾き × 作付面積 + 切片 + 誤差
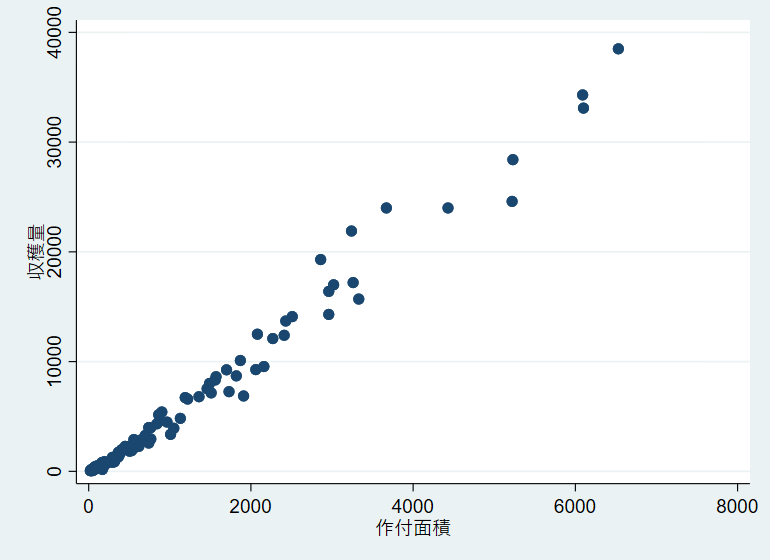
上記の式は、作付面積に比例して収穫量が変化することを想定しており、直感的にも納得できます。では、実際のデータをもとにこの2つの変数の関係を確認してみましょう。 2020年のデータにおいて収穫量と作付面積の関係を表す統計量として相関係数を計算すると0.991となり強い正の相関があります。 また、横軸を作付面積、縦軸を収穫量とした散布図は以下の通りです。
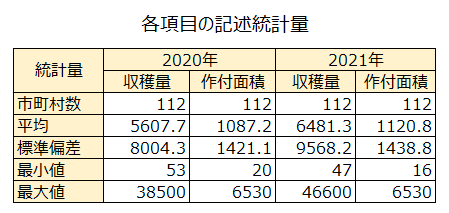
最後に各項目の記述統計量を示します。2020年と2021年の各値を比較すると、作付面積は大きく変わっていませんが、収穫量は増加していることが伺えます。
回帰分析を行う際の前提として、データ数(観測数) >> パラメータ数という関係が成り立つことを確認しましょう。
今回の例で言えば、
であり、パラメータ数に比べてデータ数が大きいといえます。
なぜこのような前提が必要なのでしょうか?
データが札幌市と旭川市の2行しかない場合を考えてみましょう。つまり、データ数とパラメータ数が等しい場合です。
このとき、下記の2式の誤差が小さくなるように傾きと切片を求めます。
与えられた等式が2つ、パラメータが2つとなり、誤差は無いもの(誤差=0)とすることができ、連立方程式として解けてしまいます。 つまり、データ数とパラメータ数が等しいとき、回帰分析ではなく単に「連立方程式を解いている」ということになるため、上記の関係が必要になります。
前項でデータの概要を確認し、統計量の算出や散布図の描画を通してデータの概要を把握しました。続いて、2020年のデータを使用して回帰分析を行いましょう。回帰分析は多くの分野で利用されている分析手法で様々なソフトウェアで実装されています。
回帰分析を実行すると、目的変数をどの程度説明できたかを表す決定係数 ( R2 )、推定結果の表などが出力されます。それぞれ確認していきましょう。

決定係数( R2 )は、0以上1以下の値をとり、値が1に近いほど目的変数をよく説明できていることを意味します。
今回の回帰分析の結果を確認すると、決定係数は、0.982となっています。決定係数が1に近いため、目的変数をよく説明できているようです。
この決定係数ですが、実は単回帰分析の場合は目的変数と説明変数の相関係数の2乗の値となります。収穫量と作付面積の相関係数は、0.991でしたが、0.9912 ≒ 0.982となり、決定係数の値と等しくなります。
推定結果の表には、回帰係数、標準誤差、t値、P値、信頼区間などがまとめられています。使用するソフトウェアにより表示形式に差異があると思いますが、一例として下記のような表が出力されます。

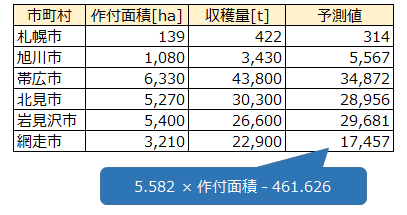
定数項と作付面積について、回帰係数、標準誤差、t値、P値、信頼区間の各値がまとめられています。この表の定数項の係数(-461.626)は回帰式の切片を表し、作付面積の係数(5.582)は傾きを表しています。 よって、推定された回帰直線の式は以下のようになります。
収穫量の予測値 = 5.582 × 作付面積 − 461.626
無事に回帰式を求めることができましたが、この推定された係数(傾きと切片)は収穫量を予測する上で意味のある数値といえるでしょうか?(言い換えると、「回帰係数は0である」ことを否定できるでしょうか?)
この疑問に答えるために、「回帰係数が0である」という仮説に対する検定結果を表から読み取ります。
検定の結果を読み取るにはP値をみればよいのですが、P値の算出には係数、標準誤差、t値が関係してきますので解説しておきます。
定数項に注目しましょう。係数は−461.626で、その散らばり度合いを示す標準誤差は127.330です。係数が−461.626ですので、0ではないと直感的に感じるかもしれませんが、標準誤差を考慮して考える必要があります。
いくら係数が大きくても(0から離れていても)、散らばり(標準誤差)も相応に大きければ、係数が0であることを否定できません。
そこで、係数を標準誤差で割った値を求めると、−461.626 ÷ 127.330 ≒ −3.625 となり、これがt値となります。t値は検定統計量であり、この値とt分布表をもとにP値が求まります。
有意水準を5%として定数項のP値を確認すると、0.000 ( < 0.05 ) なので、「回帰係数が0である」という帰無仮説は棄却されます。
よって、切片は有意な係数であると判断します。同様に、傾き(作付面積の係数)も有意であると言えます。
また、傾きや切片の推定において、係数は点推定であるのに対して、95%信頼区間は区間によって推定結果を示します。
収穫量と作付面積の散布図に推定した回帰直線を描いてみましょう。
推定した回帰直線の式に2021年の作付面積を代入して、収穫量の予測値を求めます。
次に、求めた収穫量の予測値を横軸、2021年の実際の収穫量を縦軸として散布図を描きます。予測値と実際の収穫量は値が近いほど上手く予測できている ことを意味しますが、これを確認するため縦軸と横軸の値が等しい直線を破線で表示します。
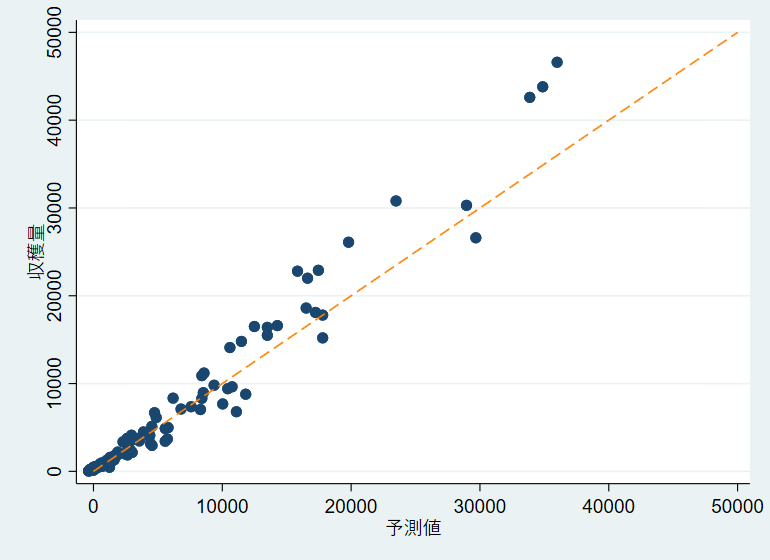
散布図を確認すると、収穫量の少ない市町村においては上手く予測できていますが、収穫量が多くなると破線から離れた市町村が複数みられます。 特にいくつかのプロットは、実際の収穫量が予測値を大きく上回っています。
収穫量と予測値の間になぜこのような差異が生まれるのでしょうか。今回の回帰分析では、収穫量を予測するための説明変数として作付面積を用いましたが、 収穫量が決まる要因として他にも重要な要素があり、それらを考慮できていないためと考えられます。
他の重要な要素として、例えば以下のような事が考えられます。
ここで行った回帰分析は説明変数が1つの回帰分析であり、単回帰分析とよばれます。 2つ以上の説明変数を用いた回帰分析は、重回帰分析とよばれます。予測の精度を高める方法として上記のような関連のありそうな項目を 説明変数として追加して重回帰分析を行い、予測を行うことが挙げられます。
ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム
© 2024 Lightstone Corp. All Rights Reserved