
予測に関するEViewsの機能を三回に分けてご紹介します。
第一回 予測平均が一番良い?
第二回 最尤法による時系列モデルの推定
第三回 ARFIMAモデル
予測平均と予測比較
第一回目にご紹介する新機能は次の2つです。最新のEViewsをお持ちでない方は、デモ版をダウンロードしてお試しください。
- 予測の平均化
- 予測の比較
EViewsでは複数の予測系列を平均化したり、比較したりすることが可能です。その操作方法を解説します。
まずは以下のデータをダウンロードしてください(製品版のEViews サンプルファイルにも同名のファイルが存在します)。
予測の平均化
ワークファイルelecdmd にあるシリーズオブジェクトelecdmd はイングランドとウェールズにおける電力需要の月次データです。
図1に示すように2005年4月から2014年4月までの実現値が入っています。

図1: 電力需要(2005年4月-2014年4月)
ワークファイルelecdmdの中には様々な手法で作成した5つの予測値(elecf_ff1, elecf_ff2, elecf_ff3, elecf_ff4, elecf_ff5) が既に用意されています。
予測した期間は2014年5月から2015年12月です。複数ある予測値の平均をとると、結局、それが一番良くなることが多い、ということを我々は経験的に知っています。
実際に5つの予測値シリーズから新しく予測値 elecdmd_f を作ってみましょう。具体的には次のように操作します。

図2: 平均作成のダイアログ
図1に示したシリーズelecdmd でProc/Forecast Averaging... として上のダイアログを表示します。
5つのシリーズ elecf_ff1 から ff5 の平均を求めますので、左上のダイアログボックスにはワイルドカードを利用して elecf_ff* と入力します。
平均化する期間 (Forecast sample) は “2014m5 2015m12” とします。
平均化の方法は単純な平均でなく、ここではMSE を利用する方法を選択し、その加重計算に必要な期間をTraining Sample のテキストボックスに “2013m5 2014m4” と入力します。
MSEの加重平均の具体的な計算方法は後述します。
このように加重平均法を利用する場合は、 Training Sample のテキストボックスで加重の計算期間を設定します。
最後に、平均化した新しいシリーズオブジェクト名を elecdmd_f としてOK ボタンをクリックします。

図3: 5つの予測値の加重平均
図3は5つの予測シリーズとelecdmd_f をグループ化して作成しました。
加重平均を取っているので、曲線は確かに真ん中あたりに位置しています。ここでダイアログで選択した項目について解説しておきましょう。
図2に Averaging method という項目があります。単純に予測シリーズの平均を計算するだけなら、計算は至ってシンプルですが、ここには次のような選択肢があります。
- Simple Mean
- 単純に予測値の各時点の平均を求めます。
- Trimmed Mean
- 予測シリーズの両端の値を除外して平均を求めます。percent のボックスには除外する上下 t % の数値を設定します。
- Simple Median
- 単純に予測値の各時点の中央値を平均として利用します。
- Least Square Weights
- 予測値を実現値に回帰して、回帰式の推定値を加重として利用します。Training Sample のテキストボックスには回帰式の推定期間を入力します (参照: Handbook of Economic Forecasting, Vol 1, page159)。
- Mean Sqaure Error Weights
- Stock-Watson(2001) の提案した方法です。予測のMSE を求め、それを利用して(1)式で加重を計算します。k は一般的1 とします。

まず、ここで言うMSE(平均二乗誤差)とは Training Sample の期間で計算した、5つの予測におけるMSE です。この期間は実現値が分かっていますので、MSE を求めることができます。
5つの予測値に対してMSE1からMSE5まで、5つのMSEを求めます。
先にも触れましたようにk = 1 として考えますと、MSEが分かれば、5つのwiも簡単に計算できます。この加重を利用して5つの予測値の加重平均を求めたものが、図3の ELECDMD_F です。 - MSE Ranks
- Aiolfi and Timmermann(2006) によるMSEランク法を利用します。
- Smoothed AIC Weights
- AIC を利用して次のような加重を計算します。

- Approximate Bayesian Model Averaging Weights
- シュワルツ情報規準を利用して加重を計算します。ただし、これを比較的小さな標本で利用すると、過度な加重を与えることになってしまうことが
分かっています。

次の3つは加重平均を計算するための加重の計算式が異なります。
次の2つは図2のダイアログで予測シリーズ名の代わりに、予測シリーズを計算するEQUATIONオブジェクト名をダイアログボックスに入力した場合に利用可能な、加重計算の手法です。
一度、話を整理しておきましょう。
個別の予測値よりも、複数の予測シリーズを色々なモデルで作成し、その平均をとったものが実現値に一番近いことがよくあり、実際、Timmermann(2006)にはこのタイプの研究が詳しく紹介しています。
予測の平均化のニーズに答えるために、EViewsでは実際に予測値の単純平均と加重平均を求める方法を新たに用意しました。
自身の作成した予測値しか利用していなかったという方は、是非、この平均化の手法をお試しください。
予測の比較
次にご紹介するEViewsの予測に関する新機能はTimmermann(2006)による組合わせ検定(Combination Test)です。
ここでも先ほどと同じワークファイルに入っているデータを利用して、まずは新機能である組合せ検定を体験してみましょう。
最初に、目的のシリーズをグラフにしてデータを確認します。elecf_fe1, elecf_fe2, elecf_fe3, elecf_fe4, elecf_fe5 によるグループオブジェクトを作成し、次のようなグラフ(図4) を作成します。期間は2013m01-2013m12 とします。

図4: 包含関係を検定する5つの予測値
図4は何らかの方法で作成した5つの予測曲線です。
この曲線間に包含関係が成り立っていないか?というのがここでの問題意識です。それでは組合せ検定によってその包含関係を調べてみましょう。
シリーズelecdmd でView/Forecast Evaluation... として次のダイアログ(図5) を表示します。
Forecast data object のテキストボックスにelecf_fe1, elecf_fe2, elecf_fe3, elecf_fe4, elecf_fe5 と入力します。

図5: 予測評価のダイアログ
OK ボタンをクリックすると図6 の結果を上部に表示します。

図6: 組合わせ検定の結果
組合わせ検定の帰無仮説は、“当該i 番目の予測値は他の予測値の情報を含んでいる”というものです。
ELECF_FE1 の予測値は有意水準5%でこれを棄却していますので、これは当てになりません。その他の 2-5 間でのシリーズは包含関係にあるようです。
それでは、ここで言う「包含関係」とはどのようなものか、この検定の枠組みをここで確認しておきます。
組合わせ検定は(4)式を推定して、βjの有意性検定を行うものです。

ここではYt+hはt時点からt+h時点間での実現値ELECDMDです。
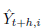 は何らかの手法で用意した ELECDMD のi 番目の予測値です。
は何らかの手法で用意した ELECDMD のi 番目の予測値です。
つまり、左辺は予測の誤差を示しています。
右辺では、それを定数項 β0 と i 番目以外の同期間の予測値でその誤差を説明しようと試みています。
N は準備した予測値シリーズの数で、ここでは5です。
βj が有意にゼロと異なれば、自分以外の予測値で誤差を説明できることになります。
検定結果からは2番から5番の予測値の誤差は、他の予測シリーズでは説明できないことを示しています。だとすると、2番から5番の予測シリーズのどれを採用したらよいでしょうか?
そこで、個別のシリーズだけを比較するのではなくで、最初に行った予測の平均化を含めて検討した結果を中段(図7) に表示しています。

図7: 予測の評価
リストを見ると、EViewsがMSEを利用した加重平均の項目にグレーの色を付けており、それが一番良いという事が分かります。
実際、当てにならない ELECF_FE1 はどの指標で見ても誤差が一番大きく、逆に MSE による加重平均法のそれは、すべての項目で誤差が一番良いことが分かります。
最後に、予測の誤差を評価する図7の指標を参考までに表1に示しておきます。

今回はEViewsの、予測の平均化に関連する機能をご紹介しました。
予測値はすでに手元にあるものとして説明を行いましたが、実際には最初にモデル式を推定し、そこから予測値を求めます。
そこで第二回では、arma項を利用した時系列モデルの新機能をご紹介します。

